
Clinicians need answers grounded in evidence — not confident-sounding text that lacks clinical support. As AI becomes embedded in clinical workflows, it is critical to measure not just whether a system responds, but whether it responds with evidence.
Today we’re sharing results from our latest benchmark evaluation. Across 5,000+ real clinician questions, Atropos Health’s integrated real-world evidence solution answered with evidence at 2–3x the rate of every general-purpose LLM tested — and adding Alexandria to a retrieval pipeline more than doubled the percentage of questions answered with evidence.
Results
Each response was rated on a three-tier scale: Green (answered with evidence), Yellow (partial or low-confidence), or Red (answer did not pass validation).
Atropos Health achieved the highest rate of evidence-based answers — by a wide margin
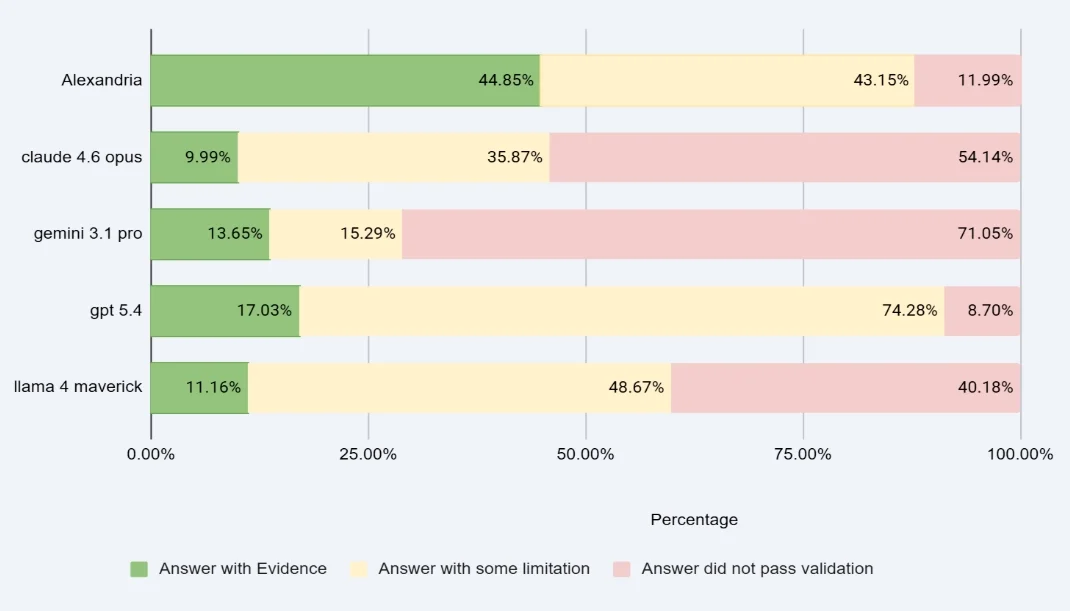
Atropos Health also leads on total evidence coverage (Green + Yellow combined)
Atropos Health returned a green or yellow response on 88% of questions — higher than others — meaning our system found something relevant to surface more often, and did so with more evidentiary grounding.
A note on our red rate
Atropos Health’s 11.99% red rate reflects a deliberate design standard: when our pipeline cannot identify sufficient real-world evidence, it declines to answer rather than generate an ungrounded response. This is a feature, not a limitation. GPT-5.4’s lower red rate (8.70%) comes at the cost of a 74% yellow rate — fluent responses that lack clinical grounding. We chose rigor over recall.
Methodology
Questions: 5,000+ real clinician questions drawn from actual clinical practice, submitted to all systems under identical conditions.
Rating scale: Responses were independently rated Green (answered with evidence), Yellow (partial/low-confidence), or Red (answer did not pass validation) using a consistent rubric across all systems, combining AI scoring with human-in-the-loop calibration.
Alexandria augmentation: The >100% improvement in questions answered with evidence reflects the delta between a standard retrieval pipeline and one augmented with pRWE™ summaries from Alexandria, measured across the same benchmark set.
Atropos Health red responses reflect prompt-level rejections when evidence was insufficient — not system errors or failures to respond.
This evaluation is part of our ongoing, publicly documented eval program for real-world evidence generation at scale. Prior evals have covered RAG quality for medical literature summarization and structured output quality for observational evidence studies.
About Alexandria
Alexandria is the world’s largest real-world evidence library, with more than 33 million precision Evidence-Based Findings (pEBF™) and growing to two billion by end of 2026. It is available now via the Atropos Evidence™ Agent on the Microsoft Marketplace and at https://portal.atroposhealth.com/order.