The Evidence Manifesto
A Vision for Medicine Rooted in Evidence, Not Tradition or Prediction
contents
Part I: Medicine Without Evidence
Part II: Evidence On Demand
Part III: Where Evidence Meets Action
Part IV: The Future We're Building
Part I: Medicine Without Evidence
I have been carrying this essay for a long time.
Not the words, those are new. But the frustration behind them, the sense that something foundational is broken and that I have a responsibility to say so, clearly and completely, that has been with me for the better part of a decade. I first started articulating the core idea in 2016, on a podcast that almost nobody heard, where I described a future in which a clinician could ask any clinical question, no matter how specific, no matter how unstudied, and receive a rigorous, evidence-based answer in real time, generated from real patient data. At the time, people thought I was describing science fiction.
I was describing an obligation.
I am a pharmacologist by training. I spent years inside the system that generates the evidence doctors rely on: designing studies, running analyses, navigating the slow machinery of research, peer review, and publication. I know how that system works. I know what it produces. And I know, with the certainty that comes from watching it fail from the inside, that it is not serving the people it was built for. Not because the people within it are failing. The researchers are brilliant. The clinicians are dedicated. The institutions are well-meaning. The system itself is the problem. It was built for a world that produced clinical questions slowly and had the luxury of answering them over years. That world no longer exists.
Today, the questions come faster than the answers. They come from clinicians facing patients whose conditions have never been studied in combination. They come from patients who upload their medical history into an AI tool and expect a personalized answer. They come from pharmaceutical companies trying to expand the use of existing drugs, and from payers trying to decide what to cover. The system that is supposed to answer those questions, the evidence system, cannot keep up. It was never designed to.
I am writing this because I believe we have reached a tipping point. The technology now exists to fundamentally change how evidence is created, trusted, and delivered. Not incrementally. Not as a marginal improvement to the existing pipeline. But as a paradigm shift, from a world in which evidence is scarce, slow, and incomplete, to one in which it is abundant, fast, and specific to the patient in front of you.
I have spent the last decade building toward this moment, carefully and methodically, because I believe it matters too much to get wrong. And I am writing this manifesto now because I believe it is time to describe, in full, what is possible, and what is at stake if we fail to act on it.
This is not about any single product or company. It is about a future for healthcare that is rooted in evidence, not tradition, not prediction, not consensus, not institutional inertia. Evidence. What it is, who it fails today, why the failure persists, and what becomes possible when we close the gap.
Section 1: The Evidence Gap
Let me start with a patient.
She has pulmonary arterial hypertension (PAH). But she does not know that yet. For years, she has been experiencing progressive fatigue and shortness of breath. She has been told she is out of shape. Then that she is anxious. She has been treated for asthma. Then COPD. Her symptoms have worsened through all of it. She has seen multiple physicians. Months have passed, then more than a year. This is not an exotic clinical presentation. It is the kind of story that plays out in pulmonology offices across the country, because the early symptoms of a rare, life-threatening vascular disease look almost identical to conditions that are far more common.
So the doctor does what doctors have been trained to do. She goes to the literature. She checks the clinical guidelines. She searches the databases. And increasingly, she asks an AI tool: one of the large language models that now promises to synthesize all of medical knowledge into an instant answer.
Finally, she is referred to a pulmonary hypertension center and correctly diagnosed with pulmonary arterial hypertension. By then, her pulmonary vasculature has been remodeling and her right ventricle has been deteriorating for the better part of two years. She has lost time that cannot be recovered. A 2024 multinational survey found that the average PAH patient waits 17 months from first symptoms to diagnosis, sees nearly three physicians, and is misdiagnosed 41% of the time. In the United States, that misdiagnosis rate exceeds 50%.1 That is the first evidence gap: the system could not recognize her disease. But there is a second gap waiting. She is started on background therapy, but she also has a history of venous thromboembolism from a complicated pregnancy. Her pulmonologist knows about Sotatercept, the first disease-modifying therapy for PAH, approved in 2024 after a pivotal trial that was stopped early because the results were too strong to withhold. But the HYPERION and STELLAR trials excluded patients with thrombotic risk. The question of whether Sotatercept is safe for her has never been studied. The evidence does not exist.
This patient, and her question, will follow us through every section of this manifesto. We will return to her as we examine who gets excluded from the evidence system, why the pipeline takes so long, how new evidence can be generated in seconds, how trust is built around it, and how it reaches the doctor at the moment of decision. She is not a hypothetical. She is the reason I am writing this.
And she is not an edge case.
Only 14% of daily medical decisions are backed by high-quality evidence.
I will say that again, because it deserves to be absorbed. Fourteen percent. The other 86% are made in the absence of it: through clinical intuition, extrapolation from imperfect analogies, institutional habit, or, increasingly, by asking an AI tool that is itself drawing from the same incomplete evidence base. These are not bad doctors making careless decisions. These are excellent doctors doing the best they can with what the system gives them. And what the system gives them, 86% of the time, is silence.
We have been calling this system “evidence-based medicine” since the term was coined in the early 1990s.2 It was a powerful idea: that clinical decisions should be grounded in the best available research rather than tradition, authority, or individual experience. And in the three decades since, an entire infrastructure has been built around this aspiration: journals, guidelines, systematic reviews, meta-analyses, evaluation frameworks. The aspiration was right. But the infrastructure has not kept pace with the reality of clinical practice.
The reality is this: the questions that doctors face every day are more specific, more complex, and more numerous than the evidence system can answer. Our pulmonologist has a patient with PAH and a thrombotic history and needs to know whether Sotatercept is safe. The trials excluded her. The reviews did not include her. The guidelines are silent. And the AI, faithfully, reports that there is no strong evidence for this population. Because there is not.
This is the norm, not the exception.
Consider what this means at scale. There are roughly one billion clinical encounters per year in the United States alone.
If only 14% of the decisions made in those encounters are backed by high-quality evidence, then hundreds of millions of clinical decisions every year are being made without the evidentiary foundation that the system claims to provide. Hundreds of millions of moments where a doctor is doing their best with insufficient information. Hundreds of millions of patients who deserve better.
Why the Gap Exists
It is important to be clear: this gap is nobody’s fault in isolation. Clinical trials are expensive. They take years. They can only test a narrow set of variables in a carefully selected population. A single randomized controlled trial can cost hundreds of millions of dollars and take a decade from conception to publication. The pace of research is what it is, and it has produced extraordinary advances over the past century.
But the pace of clinical questions is faster. Every day, across every specialty, clinicians face questions that no trial has ever addressed. Not because the questions are obscure, but because the combinatorial reality of human health, the intersections of age, sex, ethnicity, comorbidities, medications, genetics, and lifestyle, produces a space of clinical questions that is orders of magnitude larger than what the trial system can explore.
The result is a paradox: we have more medical knowledge than at any point in human history, and yet the majority of the decisions that determine patient outcomes are made without direct evidentiary support. We have built an enormous cathedral of evidence-based medicine, and most patients are standing outside it.
What Happens in the Silence
When evidence does not exist for a clinical question, doctors do what they have always done: they rely on training, experience, pattern recognition, and analogy. They look at the closest available evidence, a trial that studied a similar but not identical population, a guideline that covers a related but not exact condition, and they extrapolate. This is not malpractice. It is medicine as it has been practiced for centuries.
But it carries costs. Extrapolation introduces uncertainty. Uncertainty leads to variation in practice: different doctors making different decisions for the same patient, not because one is right and one is wrong, but because neither has the evidence to know. Variation leads to suboptimal outcomes for some patients. And suboptimal outcomes, multiplied across hundreds of millions of encounters, become a systemic problem that we have largely normalized.
We have normalized guessing. Not malicious guessing. Not negligent guessing. Educated, well-intentioned guessing by deeply trained professionals. But guessing nonetheless. And we have built an entire healthcare system, trillions of dollars, millions of professionals, billions of patient interactions, on top of it.
The question I have spent the last decade trying to answer is: what if we didn’t have to?
Section 2: The Populations Left Behind
Remember our patient, the woman with pulmonary arterial hypertension (PAH) who waited nearly two years for a correct diagnosis while being treated for asthma and COPD. She is not an anomaly. She is comorbid: she has PAH and a history of venous thromboembolism, and the interaction between her vascular disease and her thrombotic risk is precisely what makes her treatment decision complex. She is part of a population so systematically excluded from the evidence base that most patients like her will never receive care informed by evidence generated for their specific profile.
Seventy percent of U.S. patients have at least one comorbidity. They have diabetes and hypertension. Heart failure and kidney disease. Depression and chronic pain and an autoimmune condition. They are, in other words, real patients with real bodies that do not conform to the clean categories of a clinical trial protocol.
And yet, 70% of clinical trials exclude comorbid patients.
I want to sit with that for a moment. Seventy percent of patients are comorbid. Seventy percent of trials exclude them. The evidence system was designed to study patients without complications, and then it applied its findings to a population where complications are the defining feature. This is not a minor methodological limitation. It is a structural inversion: the system knows the most about the patients who need it least, and the least about the patients who need it most.
The Mechanism of Exclusion
To understand why this happens, you need to understand how clinical trials are designed. A trial’s primary goal is to isolate the effect of an intervention, to determine whether Drug A works better than Drug B for a specific condition. To achieve that isolation, the trial must control for confounding variables. And the most common way to control for confounding variables is to exclude patients who have them.
Our patient was excluded from the Sotatercept trials because her thrombotic history could complicate the safety analysis. A patient with abnormal hemoglobin or hematocrit is excluded because it could confound the hematological endpoints. A patient with bleeding risk is excluded because it could obscure the treatment effect. One by one, the patients who most resemble the real clinical population are screened out so that the trial can produce a clean result.
The trial succeeds on its own terms. It produces a statistically rigorous answer to a carefully bounded question. But the patients who were excluded, the complex ones, the comorbid ones, the ones whose doctors will most desperately need guidance, are left with nothing. The evidence was never generated for them.
Who Falls Through
Comorbidity is the primary mechanism of exclusion, but it cuts across every demographic axis of healthcare. Consider the populations most affected.
The elderly
Nobody runs clinical trials in the elderly because they are, almost by definition, multi-comorbid.3 A typical geriatric patient might be on seven medications for five conditions. They are precisely the patients for whom drug interactions, dosing decisions, and treatment sequencing matter most, and they are precisely the patients for whom the evidence base is thinnest. I think about my own grandparents, the number of medications on their kitchen counter, the complexity of the decisions their doctors face, and I think about the fact that the evidence for almost none of those medications was generated on patients who looked anything like them.
At Stanford, the geriatrics department reached a point where they mandated that trainees learn to use real-world evidence generation tools, because there was no other way to practice evidence-based medicine for their patient population. The traditional evidence simply did not exist. That fact alone should tell you everything you need to know about the state of the system.
Women
Women have been historically underrepresented in clinical trials.4 And when they are included, comorbid women, women with multiple chronic conditions, women on complex medication regimens, women with conditions that interact with hormonal factors, are excluded at even higher rates. The result is a body of evidence that was generated predominantly on men, or on women without the complications that characterize real clinical populations.
Children
Racial and ethnic minorities
They Are in the Data
Here is what I find most frustrating about this: the patients who are excluded from clinical trials are not invisible. They exist in the healthcare system. They have medical records. They have claims data. They have treatment histories and outcomes that are documented in electronic health records across the country. We can see them. We can see what happened to them. We can see which treatments they received and how they responded.
The data exists. What does not exist is the evidence, the structured, rigorous, peer-reviewable analysis that converts that data into knowledge a clinician can act on. And for most of the history of medicine, that conversion process has been too slow, too expensive, and too narrow to reach these patients.
Our patient is in the data. Tens of thousands of PAH patients are in the data, including patients with thrombotic histories, patients on complex combination regimens, patients whose outcomes were recorded over months and years. Everything a pulmonologist would need to answer the question is already sitting in the system. It has simply never been converted into evidence.
The question that drives everything I do is simple: if the data is there, and the patients are in it, why are we not producing the evidence? What are we waiting for?
Section 3: The Five-Year Bottleneck
Suppose a researcher heard about our patient, the woman with pulmonary arterial hypertension (PAH) and a thrombotic history, the question no trial has answered, and decided to do something about it. Suppose they were motivated, funded, and ready to run the study that would fill this gap. How long would it take for that evidence to reach her pulmonologist?
The answer, in the current system, is approximately five years.
Let me trace the journey. The researcher writes a grant proposal and submits it for review. If funded, and most proposals are not, they assemble a research team, negotiate data access with one or more institutions, and begin designing the study. They work with data stewards to build patient cohorts. They iterate on definitions, determine the right dataset, design the analysis with a data science team, run the first analyses, and begin the long process of reviewing outputs, refining methodology, and drafting a manuscript.
This research phase alone, from study question to finalized manuscript, takes, on average, ten months or more in the traditional process.7
That is just the research. Once the study is complete, it enters the publication pipeline. Manuscript drafting, internal review, journal submission, peer review, revision, resubmission. This process typically takes six months, often longer. Now the evidence is published. But published is not the same as practiced.

The relevant specialty guideline committee must evaluate the new evidence and decide whether to update its recommendations. This process occurs on its own cycle, often annually, sometimes less frequently, and committees are naturally conservative. New evidence must accumulate and be weighed against existing recommendations before guidelines change. Another six to twelve months pass, if the evidence is incorporated at all.
Once guidelines are updated, clinical practice begins to shift, but slowly. Physicians must become aware of the change, trust it, and integrate it into their workflows. Another twelve months, conservatively. And finally, payers must evaluate the new standard of care and decide whether to update their coverage policies. Another cycle, another review, another delay.
From idea to reimbursed practice: approximately five years. Five years for one piece of evidence to travel from a researcher’s mind to a patient’s bedside. And during those five years, every patient with that combination of conditions was treated without it. Including our patient.
What the Guidelines Actually Contain
The consequences of this bottleneck are visible in the guidelines themselves. An analysis of citations in active 2024–2025 clinical guidelines reveals a striking pattern: 45% of all cited evidence originates from 2018–2020. Another 23% from 2021–2022. Only approximately 3% from the last two years.8 And 9% from before 2015: evidence more than a decade old, still governing today’s care.
The guidelines are not just slow to update. The evidence they draw from is overwhelmingly four to six years old at best. This is not a criticism of guideline committees, they can only incorporate what exists, and what exists is the product of a pipeline that moves at the speed I have described.
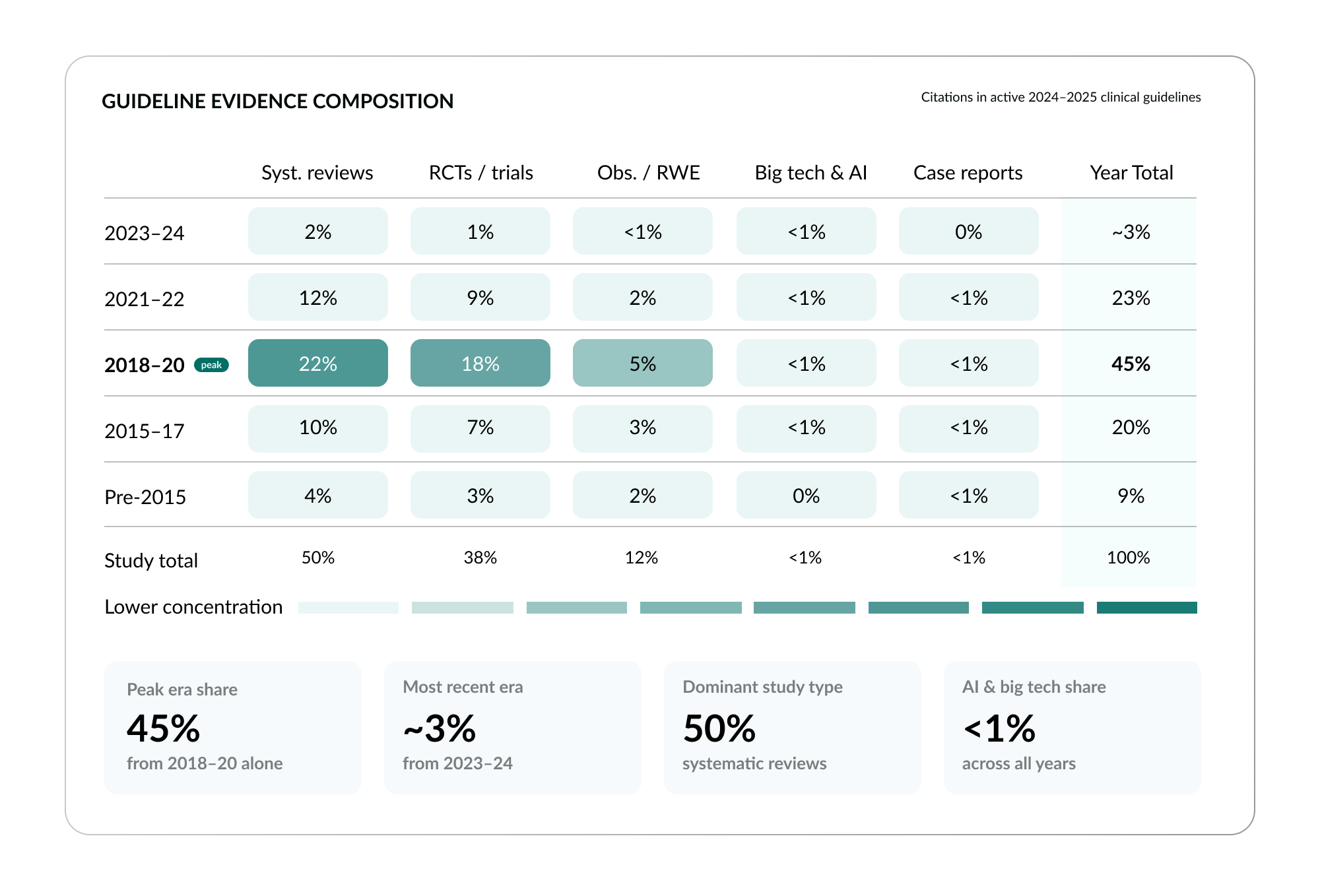
The study type composition of current guidelines reveals another dimension of the problem. Systematic reviews account for 50% of guideline citations. Individual RCTs account for 38%. Observational research and real-world evidence account for just 12%.9 And evidence from AI or technology-driven approaches accounts for less than 1%. The guideline system is built almost entirely on two evidence types, with real-world evidence barely represented and AI-generated evidence essentially invisible.
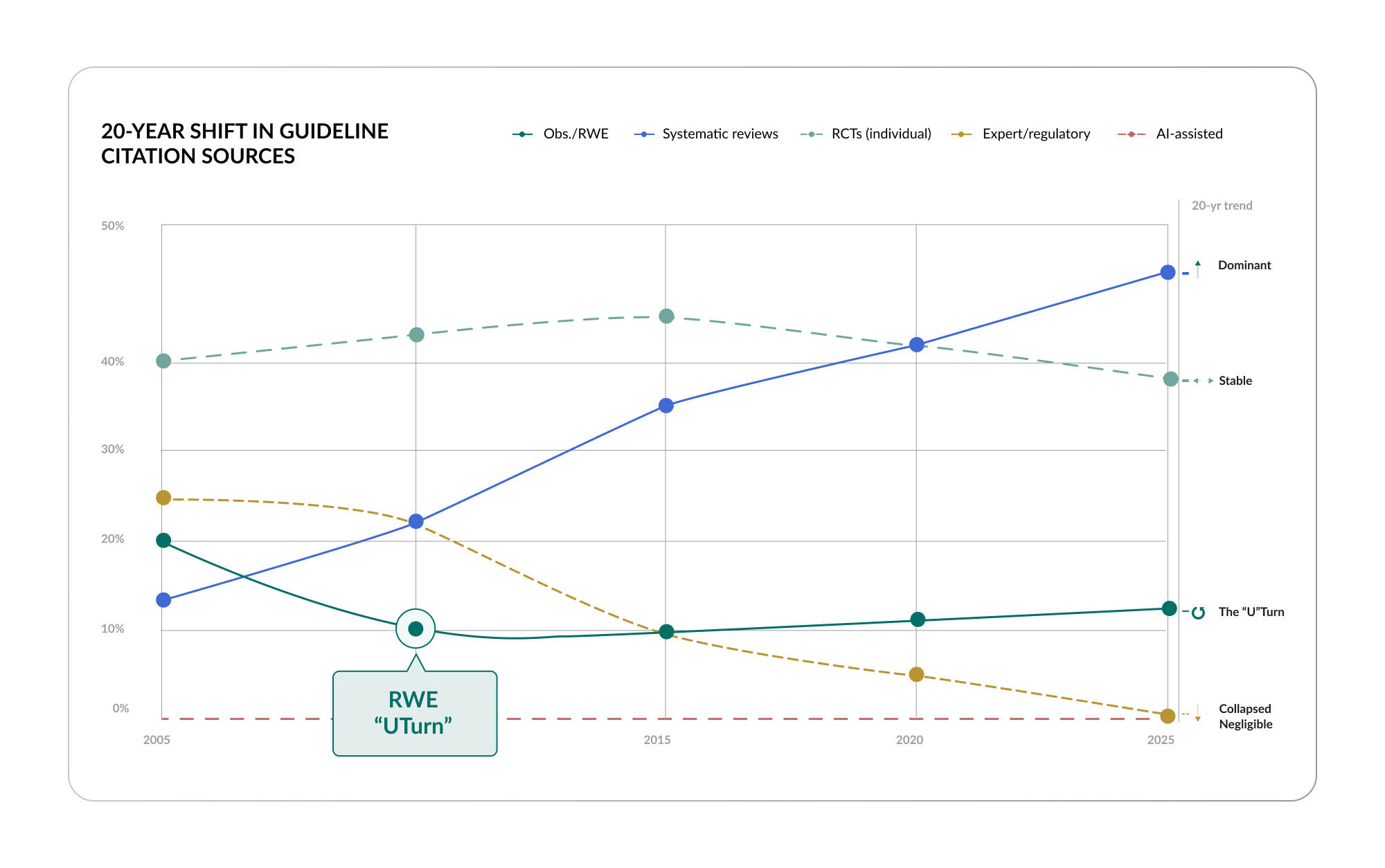
The 20-year trend is revealing. Systematic reviews have risen from less than 15% of guideline citations in 2005 to 50% in 2024: now the dominant type. RCTs have held roughly stable. And observational evidence shows what the data describes as a “U Turn”: it was 20% in 2005, dropped to 10% by 2015, and is now climbing back to 12%.10 Expert opinion, which once accounted for 25% of guideline citations, has collapsed to less than 1%. The system is concentrating on fewer evidence types, and the types it relies on are the ones with the most structural limitations for complex, comorbid patients: exactly the patients we discussed in Section 2.
The Payer Divergence
There is, however, an important counterpoint to the guideline picture, and it foreshadows a tension that will run through the rest of this manifesto.
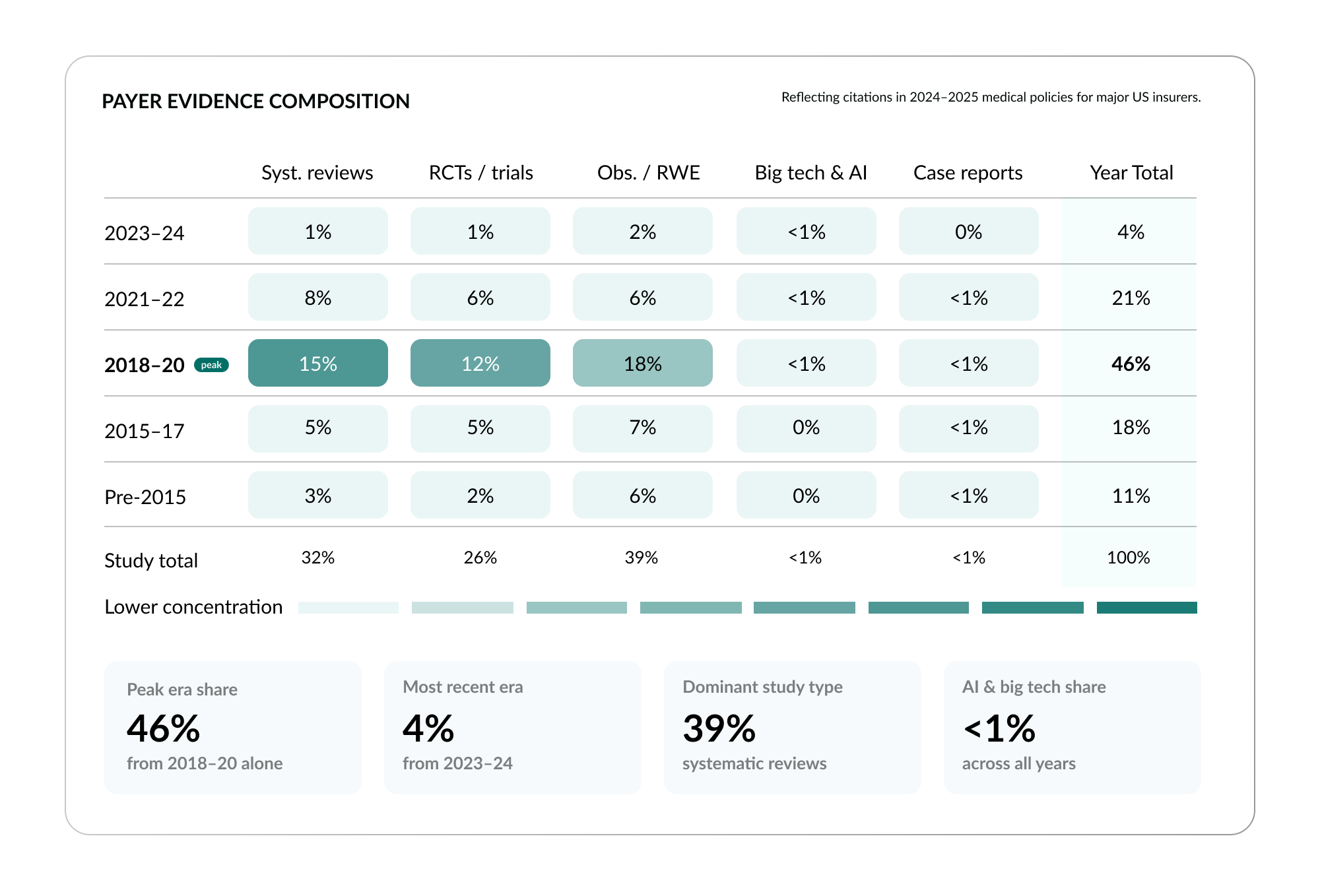
When you look at how payers, the insurance companies that make coverage and reimbursement decisions, cite evidence in their own policies, a very different pattern emerges. In 2024–2025 medical policies from major U.S. insurers, observational and real-world evidence is the single largest evidence category, accounting for 39% of all citations: more than systematic reviews at 32% and more than individual RCTs at 26%.11
The 20-year trend confirms this shift. Real-world evidence in payer policies has grown from 25% in 2005 to 39% in 2024, making it the dominant citation type.12 Payers, who must make practical decisions about coverage for real patient populations, populations that include the comorbid, the elderly, the complex, have moved toward the evidence type that best reflects real-world clinical reality.
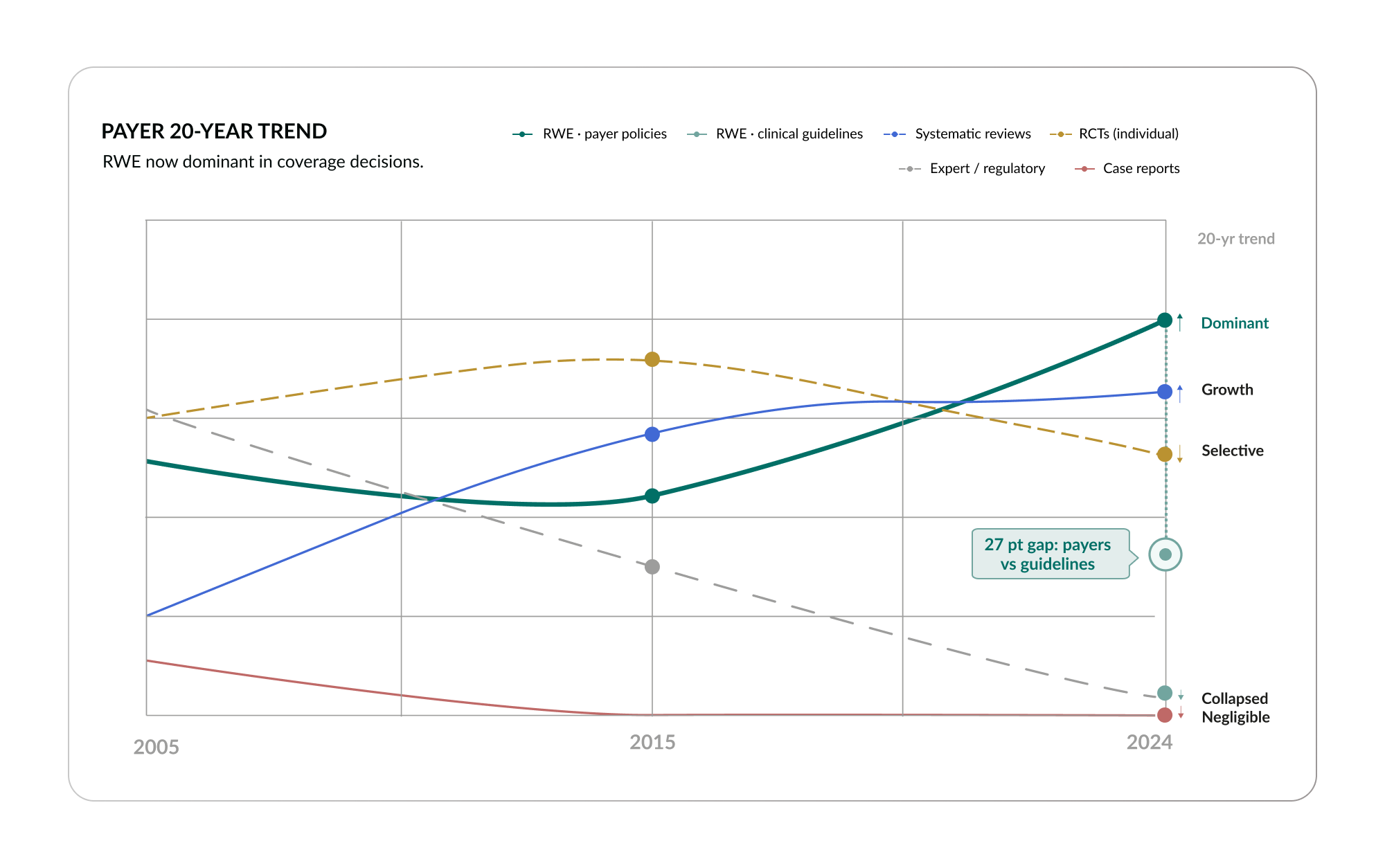
The divergence between guidelines and payers is one of the most important structural dynamics in healthcare today. The economic infrastructure, the system that decides what gets paid for, has already recognized real-world evidence as its most valuable source. But the clinical guideline infrastructure, the system that tells doctors what to do, has not kept pace. Real-world evidence remains at just 12% of guideline citations, compared to 39% on the payer side.
The clinician is caught in the middle. They follow guidelines that cite evidence from 2018–2020 and rely primarily on systematic reviews and RCTs. Meanwhile, the payer evaluating their treatment decisions is working from a broader, more current evidence base that already includes substantial real-world evidence. When a pulmonologist submits a prior authorization request for Sotatercept for our PAH patient with thrombotic risk, they may be citing guideline-based evidence that the payer’s own policies have already moved beyond. This is a system at war with itself, and the patient is the one who pays the price.
Evidence as the Currency of Value
Every relationship in the healthcare system runs on evidence. Payers set formulary and benefit positions based on evidence of drug efficacy and cost-effectiveness. Providers enter value-based contracts with payers based on evidence of outcomes and quality. Pharmaceutical companies seek regulatory approval based on evidence of safety and efficacy. Doctors make shared treatment decisions with patients based on the best evidence available. And the FDA regulates all of it.
Evidence is not merely information. It is the currency of value in healthcare, the medium through which every actor in the system transacts. When that currency is incomplete, outdated, or absent for the majority of clinical decisions, every transaction in the system is degraded. Payers make coverage decisions without full information. Doctors make treatment decisions without direct evidence. Patients receive care that is based on extrapolation rather than knowledge. And the system as a whole spends trillions of dollars on a foundation that is, in the most literal sense, evidence-poor.

The five-year bottleneck is not just an inconvenience. It is the rate-limiting step of the entire healthcare economy. And it raises a question that I believe can no longer be deferred: what if that timeline was not five years, but a month? What if it was a week? What if the evidence our PAH patient’s pulmonologist needs tomorrow could be generated today?
That question is no longer hypothetical. And the answer is the subject of Part II.
Part II: Evidence On Demand
Part I described the problem: an evidence system that fails 86% of clinical decisions, excludes 70% of patients by design, takes five years to deliver what it does produce, and is built on an infrastructure that the economic side of healthcare has already outgrown. The problem is structural. It will not be solved by working harder within the existing system. It requires a different approach entirely.
Part II describes that approach. It is not a theoretical proposal. It is a description of capabilities that exist today and are scaling rapidly: capabilities I have spent the last decade helping to build, not because I thought they would be interesting, but because I believed they were necessary.
The shift I am describing is simple to state and profound in its implications: the move from retrieving existing evidence to generating new evidence on demand. Retrieval summarizes what is known. Generation discovers what is not known yet. Every major advance in evidence-based medicine over the next decade will be built on this distinction.
Section 4: The Shift from Retrieval to Generation
Return to our patient, the woman with pulmonary arterial hypertension (PAH) and a thrombotic history, the one whose question no source could answer. In Part I, I described the silence she encountered: the literature had nothing on Sotatercept safety for patients with her risk profile, the guidelines were mute, the AI tools faithfully reported the absence. But I did not explain why. The answer is not that the question was too hard. The answer is that every tool available to her pulmonologist was built to do one thing: retrieve. And retrieval has a ceiling.
This section traces both halves of the shift that I believe defines the next era of medicine. First, where retrieval hits its structural limit. Then, what becomes possible when you move beyond it.
4A: The Retrieval Ceiling
When a clinician faces a question today, the default approach is retrieval. Search the published literature. Consult the guidelines. Query a systematic review database. Ask a large language model. Every one of these sources draws from the same underlying pool: what has already been studied, written, peer-reviewed, and published. Retrieval can synthesize, summarize, and surface this existing knowledge with increasing sophistication. But it cannot create knowledge that does not exist.
This is not a criticism of retrieval systems. They are valuable. A well-designed clinical reference tool or a well-prompted LLM can save a clinician hours of literature searching. But their value is bounded by the completeness of the evidence base they draw from. And as we established in Part I, that evidence base is profoundly incomplete.
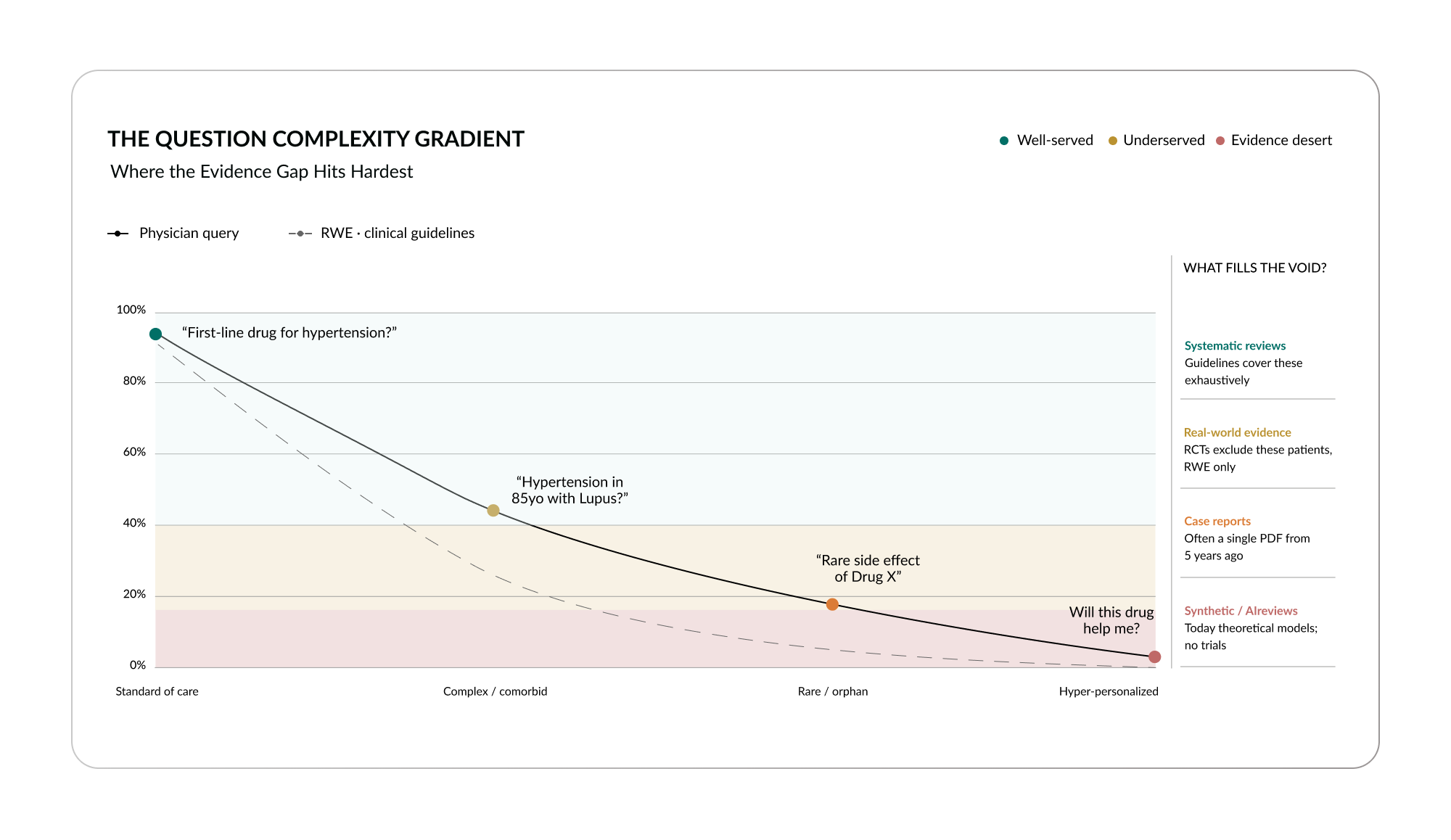
The incompleteness is not uniform. It follows a gradient of question complexity.13 For standard-of-care questions, “What is the first-line drug for hypertension?”, evidence exists roughly 93% of the time. Retrieval works well here. The trials have been run, the guidelines are clear, and any competent tool can surface the answer.
But as questions become more specific, the evidence thins rapidly. For complex, comorbid patients, “What about hypertension in an 85-year-old with lupus?”, the probability of evidence existing drops to approximately 44% for a physician query and just 25% for a patient asking the same question. For rare or orphan conditions, it falls further: about 18% for physicians, less than 5% for patients. And for hyper-personalized questions, “Will this diet fix my fatigue, given my specific combination of conditions and medications?”, the probability is near zero.
The gap widens precisely where patients need answers most. The standard patient, the textbook case with one condition and no complications, is well served by the existing evidence system. The real patient, the one with multiple conditions, multiple medications, and a clinical profile that has never been studied in combination, is not.
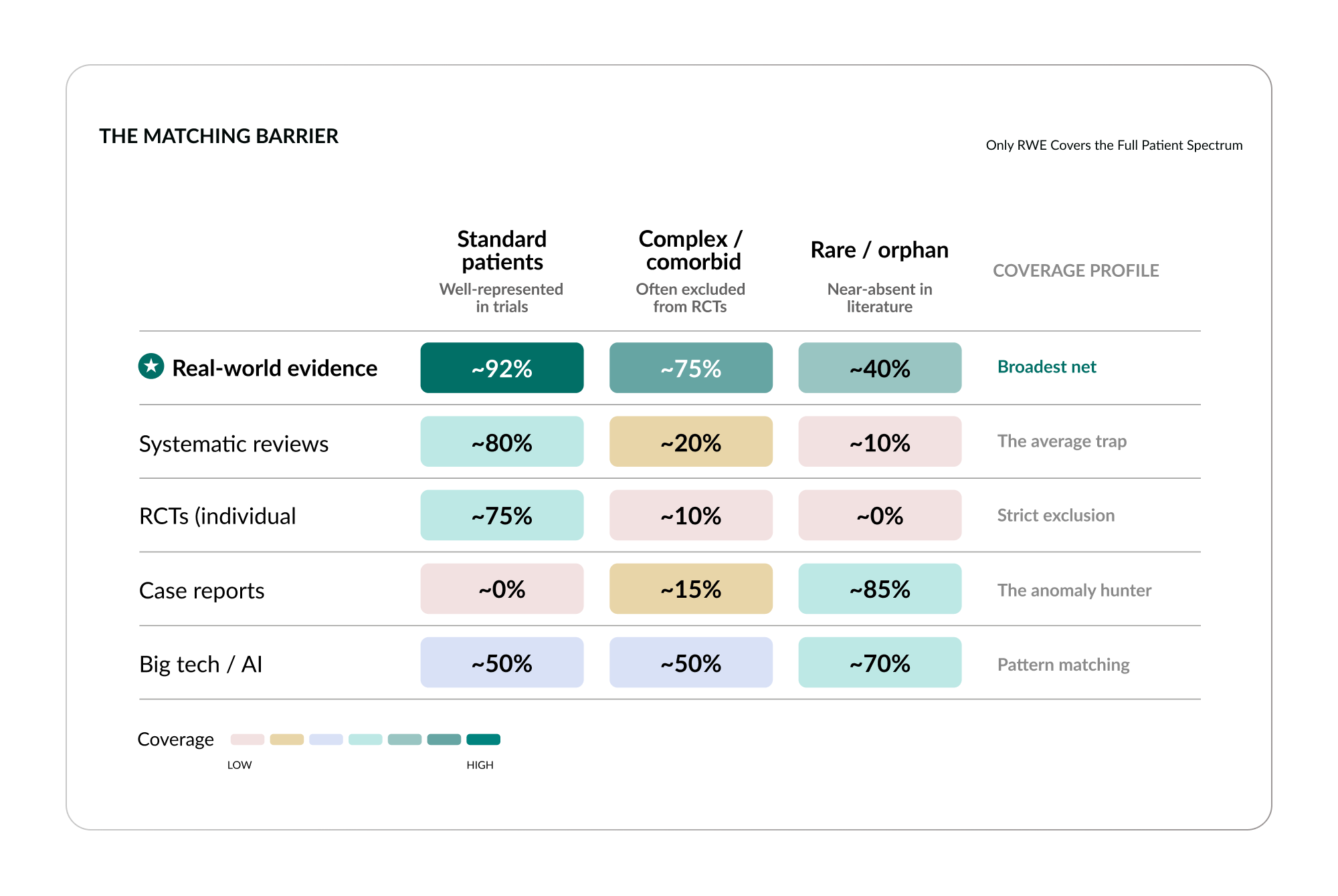
The structural reasons for this are visible when you examine how each study type performs across patient complexity.14 I think of these as matching barriers: structural features of each evidence type that prevent it from serving the patients who need it most.
Systematic reviews fall into what I call The Average Trap. They aggregate trial results into population-level averages, which means they perform well for standard patients, about 80% coverage, but drop to roughly 20% for complex patients and less than 5% for rare conditions. The average describes nobody in particular, and the patients who most need specific answers are invisible in it.
Randomized controlled trials enforce what I call Strict Exclusion. They are designed to isolate variables by excluding confounders, which means excluding complex patients. Coverage is high for standard patients, around 75%, but drops below 10% for complex patients and approaches zero for rare conditions. The patients who are excluded to make the trial work are the patients who need the evidence most.
Case reports are The Anomaly Hunter, they exist almost exclusively for the unusual and the rare, with almost no coverage for standard or complex patients. And AI models, for all their power, offer Pattern Matching, they detect patterns across massive datasets but have no evidentiary trials behind their conclusions. They can correlate. They cannot prove.
There is only one study type that maintains meaningful coverage across the full spectrum of patient complexity: real-world evidence. It scores above 90% for standard patients, approximately 75% for complex patients, and around 40% for rare conditions. It casts the broadest net because it draws from the broadest data: real patients, in real healthcare systems, with real outcomes. It captures the 95% of patients who were excluded from the clinical trials.
But here is the critical point: even real-world evidence, in its traditional form, is still a retrieval activity. A researcher identifies a question, builds a study, runs the analysis, and publishes the result. The methodology is sound. But it is still slow, still expensive, and still limited by the bandwidth of the researchers who do the work. What changes everything is what happens when the generation of real-world evidence is no longer a manual research project, but an automated, scalable, real-time capability.
That is what I mean by moving from retrieval to generation. And it is the subject of what I cover in the following section.
4B: The Conversion Engine
Let me return to our patient one more time. Her pulmonologist asked whether Sotatercept is safe to add to her regimen, given her history of venous thromboembolism. Every retrieval system returned silence. Now imagine a different tool, one that does not search the literature, but instead runs a new study.
This tool looks at hundreds of millions of real patient records. It identifies PAH patients with thrombotic histories across real-world data, including patients who received Sotatercept alongside background therapy and patients who did not. It compares their outcomes over time: functional class changes, walk distance, right ventricular function, hospitalizations, and thrombotic events. It applies the statistical methods you would expect of any rigorous observational study, propensity matching to control for confounders, sensitivity analyses to test robustness, confidence intervals to quantify uncertainty. And it does all of this in approximately twenty seconds.
The result is not a prediction. It is not an extrapolation. It is not a best guess. It is a new piece of evidence, a study that did not exist twenty-one seconds ago, generated from real patient data, with the methodological rigor of a peer-reviewed publication. And in this case, the evidence shows that Sotatercept appears safe and effective for PAH patients with thrombotic histories. The question that had no answer now has one.
This is not a new methodology. Observational research on real patient data, using electronic health records, claims databases, and other clinical data sources, has been a recognized approach for over forty years.15 What is new is the speed, the scale, and the automation. What used to take a team of researchers six to nine months can now be done in seconds. And it can be done not once, but millions of times.
The technology to do this was originally developed at Stanford, in collaboration with my co-founder, Nigam Shah, MBBS, PhD.16 The original system ran on Stanford’s own electronic health record data. Today, the evidence network spans 894 million patient timelines17 across multiple data modalities, EHR data, claims data, omics data, and imaging, maintained through a federated architecture that keeps data behind each institution’s firewall. We do not buy or sell patient data. We do not move it. The technology installs within the health system’s own infrastructure, and the evidence is generated where the data lives.
The scale of what this makes possible is difficult to convey without numbers, so let me offer some.
In the fourth quarter of 2025, this approach produced over 33 million study equivalents.18 To put that in context: there are approximately 37 million studies total in all of PubMed, the entirety of published biomedical literature in the history of medicine.19 In a single quarter, the output of evidence generation eclipsed the entire accumulated evidence base of modern medicine.
As of March 2026, the run rate is approximately 930 million study equivalents.20 The projection for the end of 2026 is 2 billion.21
These numbers are large enough to sound abstract, so let me make them concrete. How do you go from 33 million to 2 billion? One of the primary mechanisms is subgroup analysis. You take a question like the Sotatercept safety question for PAH patients, and instead of running it once, you run it across every clinically meaningful patient subgroup: patients with thrombotic histories. Patients with bleeding risk. Patients with abnormal hematological profiles. Patients on different background therapy combinations. Patients diagnosed early versus late. Each subgroup produces a distinct answer, a distinct piece of evidence, matched to a specific patient profile. The evidence gap does not close by producing one giant study. It closes by producing millions of specific ones.
And the library is not static. As new treatments enter the market, as new patient data accumulates in health systems, the evidence refreshes. This is a living system, not an archive. It grows, it updates, and it compounds. Every question that is answered makes the next question more likely to already have an answer waiting.
I want to be honest about what this is and what it is not. Each generated study is observational, it is retrospective, based on what happened to real patients, not on a prospectively designed experiment. It is not an RCT. The manifesto is not arguing that generated real-world evidence replaces randomized controlled trials. The argument is different, and I believe it is more important: the right comparison is not generated evidence versus an RCT. It is generated evidence versus no evidence at all. And for 86% of clinical decisions, that is the actual choice.
What Evidence Generation Must Support
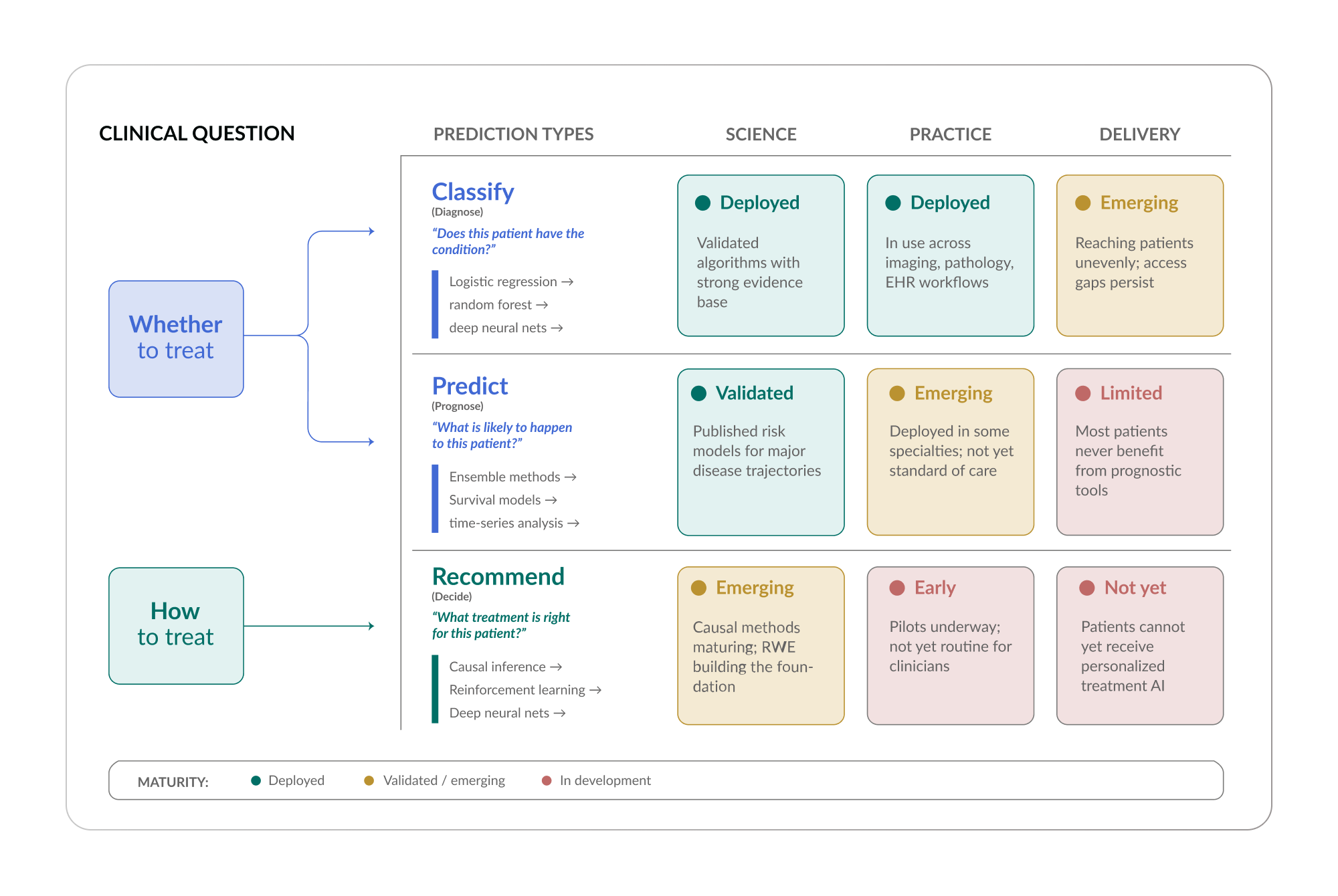
Evidence generation is not a single capability. To serve clinical practice, it must support three distinct layers of decision-making.
Classification: Does this patient have the condition?
This is the diagnostic layer: identifying what is wrong. The underlying models range from logistic regression to deep neural networks, depending on the data available and the complexity of the condition.
Prediction: What is likely to happen?
This is the prognostic layer: forecasting disease progression, risk of complications, expected outcomes. These models often use ensemble methods and time-series analysis to capture the trajectory of a patient’s condition.
Recommendation: What treatment should be used?
This is the treatment decision layer: comparing interventions for a specific patient profile. This is where causal inference methods are most critical, because the question is not just what correlates with better outcomes, but what causes them.
Each of these layers is at a different stage of maturity. Some are already deployed in clinical settings. Others are still being validated. The manifesto is not claiming that every capability is fully realized today. It is claiming that the trajectory is clear, the foundation is proven, and the pace of progress is accelerating.
The methodology behind all of this has been published in peer-reviewed journals including the Journal of Clinical Oncology, NEJM Catalyst, JACC, Health Affairs, JAMIA, npj Digital Medicine, JAMA Otolaryngology, and OFID, with a decade of method publications establishing transparency and reproducibility. This is not a black box. Every step of the process is documented, citable, and open to scrutiny.
Section 5: Beyond the Patient in Front of You
Everything I have described so far addresses a reactive problem: a patient is in the exam room, a question is asked, and evidence is needed now. But there is a deeper opportunity: one that I believe will define the next phase of what evidence generation makes possible.
Consider our patient again. She has pulmonary arterial hypertension (PAH) and a thrombotic history, and her pulmonologist is deciding whether to add Sotatercept. The evidence generation approach I described in Section 4 can answer that question in seconds. That alone is transformative. But what if we could have answered a different question two years earlier?
What if, before her PAH was finally diagnosed, when she was still being treated for asthma and COPD, we could have identified that her symptoms did not fit those conditions, that her hemodynamic patterns were consistent with early pulmonary vascular disease, and generated evidence showing that patients with her profile who were referred to a PH center at that stage had significantly better long-term outcomes? What if the evidence existed not just for the patient in front of you, but for the patient who will be in front of you two years from now?
This is the shift from reactive evidence to predictive and preventive evidence. And it broadens the definition of the evidence gap in a way that I think is profound.
The evidence gap, as I described it in Part I, is about the absence of answers for the clinical questions being asked today. But there is a second gap, a temporal one. It is the gap between when a patient could benefit from evidence-informed intervention and when they actually receive it. For many conditions, this gap is measured in years. A patient develops Alzheimer’s disease and receives a diagnosis. At that point, we can generate evidence about which treatments are most effective for patients with their profile. That is valuable. But by the time Alzheimer’s is diagnosed, significant neurological damage has already occurred. The intervention that would have made the most difference, the one that could have slowed or prevented the progression: needed to happen years earlier.
The same pattern holds for cardiovascular disease, for many cancers, for metabolic conditions, and for autoimmune disorders. The window of greatest therapeutic opportunity often precedes the diagnosis. And the evidence system, as currently constructed, only activates after the diagnosis is made.
What if it didn’t have to?
The infrastructure for predictive evidence is beginning to emerge. As evidence generation scales, from millions to billions of patient-matched studies, it becomes possible to identify patterns that precede diagnosis. Which patients showing fatigue and breathlessness have hemodynamic markers that correlate with early PAH rather than asthma or COPD? Which patient profiles benefit from earlier referral to a PH center? These are questions that can be answered from the same real-world data that powers the reactive evidence I described in Section 4.
And the data vectors are expanding. Today, evidence generation operates primarily on clinical data, EHR records, claims, and structured health data. But the future includes data from wearable devices, continuous monitoring, genomics, and other sources that capture patient health in real time. When a fitness tracker detects an anomalous heart rate pattern, that signal could be cross-referenced against generated evidence for patients with similar profiles, potentially triggering an early intervention years before a clinical event.
I want to be careful not to overclaim here. The integration of wearable and device data into evidence generation is not operational today. It is a horizon capability. But the foundation is being laid: the evidence library is growing, the data modalities are expanding, and the analytical methods are maturing. The shift from reactive to predictive evidence is not science fiction. It is the logical next step of an infrastructure that is already producing evidence at a scale that would have been unimaginable five years ago.
The moral dimension of this is worth naming. If we have the ability to generate evidence that could identify at-risk patients before they are diagnosed, and we choose not to, that is a different kind of failure than the one I described in Part I. In Part I, it’s a failure of infrastructure: the system cannot keep up. The predictive failure would be a failure of will: the infrastructure exists, and we do not use it. I do not intend for that to happen.
Section 6: The Architecture of Trust
Let me return to our patient’s generated study one more time. In twenty seconds, a new piece of evidence was created: Sotatercept appears safe and effective for pulmonary arterial hypertension (PAH) patients with thrombotic histories, based on a comparison of real-world patients. The doctor can see the result. But before they act on it, they need to trust it. And they should.
Trust in evidence is not a binary state. It is not something you have or do not have. It is a stack, a series of layers, each building on the last, each visible and auditable. And the architecture of that stack is, I believe, one of the most important things we build. If the evidence generation I described in Section 4 is the engine, the trust architecture is what makes it safe to drive.
My colleague Dr. Saurabh Gombar, cofounder and Chief Medical Officer of Atropos Health, published a very insightful piece about the importance of sound methodology and transparency when generating evidence. It’s worth a read, particularly in the context of this section.
There is a phrase that has become common in my industry, and I think it captures something true: the evaluation is the product. In an era when AI can generate answers to almost any question, the scarce resource is no longer answers. It is trustworthy answers. The system that can demonstrate, transparently and rigorously, that its outputs are reliable is the system that clinicians will adopt. Everything else is noise.
Let me describe how I think about building that trust, layer by layer.
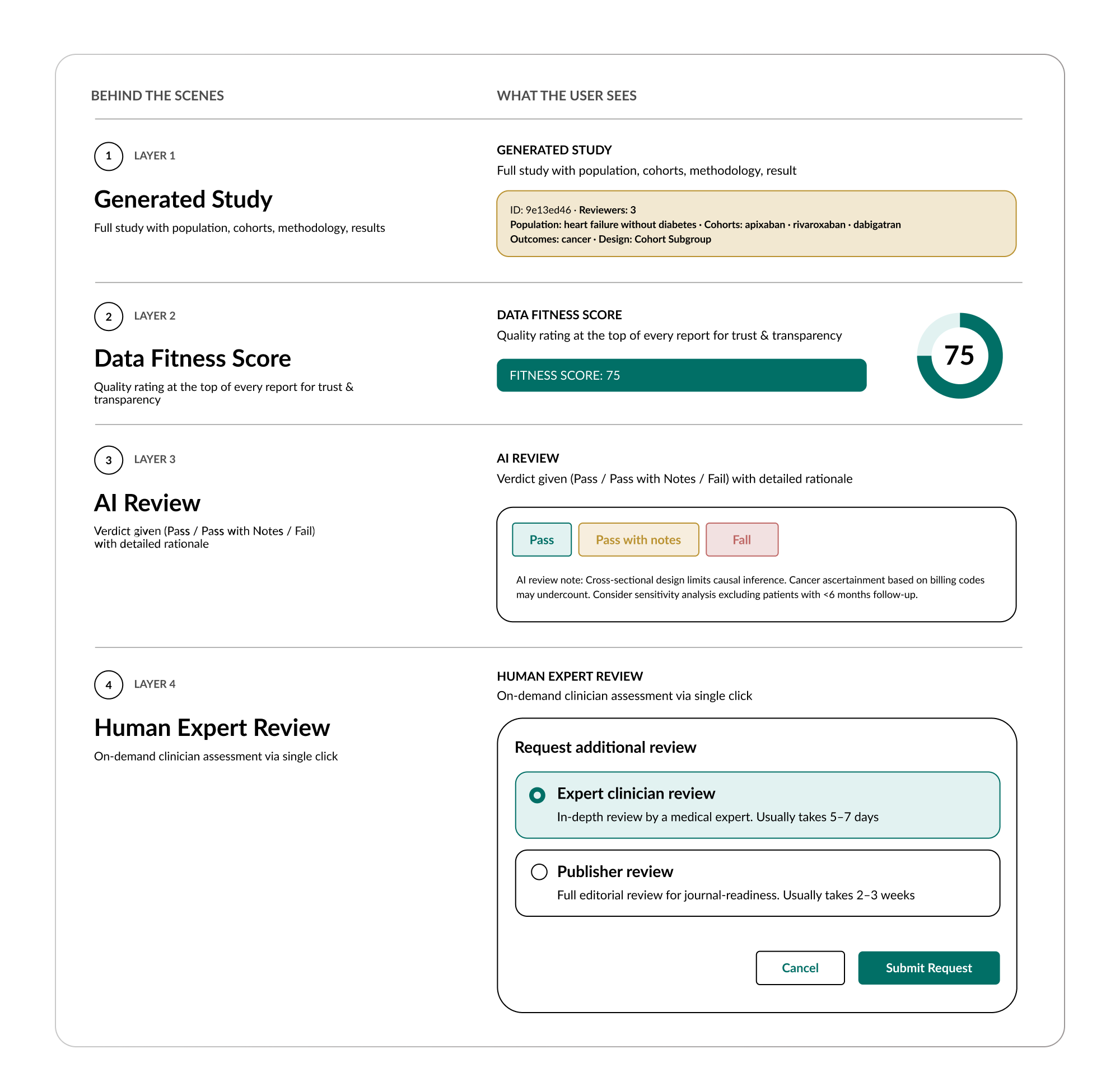
Layer 1: Methodological Transparency
Transparency is not a feature. It is the foundation. Without it, nothing else in the trust stack matters.
Layer 2: Data Fitness Scoring
Not all data is equally suited to every question. If a health system sees very few oncology patients, using their data to answer an oncology question will produce a low-quality result, not because the methodology is wrong, but because the data does not contain enough relevant patients. The evidence is only as good as the data it is drawn from. This is a statement that the healthcare industry has heard many times, and it is right to be skeptical, because very few systems actually do anything meaningful about it.
The skepticism is warranted. Healthcare data is messy. It is fragmented across institutions, inconsistent in how it is coded, riddled with gaps in documentation, and shaped by the incentives of whoever recorded it. It’s even riddled with emojis.24 Claims data reflects billing logic, not clinical reality. EHR data reflects what a physician had time to document, not the full picture of what happened. Lab results may be missing. Follow-up periods may be incomplete. Diagnoses may be coded for reimbursement purposes rather than clinical accuracy. Anyone who has worked with healthcare data at scale knows this. And anyone who claims their data is clean is either not looking closely enough or not being honest.
This is why data quality is not a feature that gets added at the end. It is an infrastructure investment that begins before a single study is generated. The evidence network I described in Section 4 is built on a data architecture that addresses quality at multiple levels: standardization of coding across institutions, validation of clinical concepts against established ontologies, identification and handling of missing data, and continuous monitoring of data completeness and consistency across the network. This work is not glamorous. It does not make headlines. But it is the difference between evidence you can trust and evidence you cannot, and it consumes a significant portion of the engineering and clinical effort behind the entire system.
On top of that infrastructure sits the data fitness score, a quantified assessment visible at the top of every generated study that indicates how well-suited the underlying data was for the specific question asked. This is not a generic quality badge. It is question-specific. The same dataset might score high for a cardiovascular question and low for a rare oncology question, because the relevant patient population, the follow-up duration, and the outcome completeness are different for each.
Think of it as a credit score for the evidence. A high score means the data contained a large, relevant patient population with sufficient follow-up, adequate outcome capture, and appropriate covariate coverage to support the analysis. A low RWFS does not mean the data is bad. It means the data is not well-matched to this particular question, and the results should be interpreted with caution or the study should be run on a different dataset within the network.
This is something that no other AI system in healthcare provides. When you ask a large language model a clinical question, you receive an answer with no indication of how confident you should be in the underlying data, because the model has no concept of underlying data. It has training weights. You get the answer, but not the quality signal. Data fitness scoring changes that. It does not just tell you what the evidence says. It tells you how much you should trust it for this specific question, and it shows its work.
Layer 3: AI Review
Every study generated through this system undergoes automated AI review, and I mean that literally. It is not a confidence score. It is not a quality flag. It is a full, structured, multi-reviewer critique modeled on the academic peer review process.
The AI review evaluates each study across multiple dimensions: methodological correctness, arithmetic verification, verification of the numbers against the underlying cohort data, appropriateness of causal claims, baseline balance across comparison groups, consistency of follow-up duration, and whether external literature exists to contextualize the findings.
The output is a structured verdict: Pass, Pass with Notes, or Fail. A study that is methodologically sound with no concerns receives a clean Pass. A study with minor gaps, for example, baseline imbalances between cohorts that are not acknowledged in the summary, or missing external context, receives a Pass with Notes, along with a detailed explanation of what was flagged. A study with critical methodological problems receives a Fail and is not delivered to the user.
The Pass with Notes verdict is, I think, the most important feature of this system. It means the review catches nuance, not just errors. It means the system does not rubber-stamp its own output. A system that always says “Pass” is not trustworthy. A system that distinguishes between a clean pass and a qualified pass, with specific, readable reasoning, earns trust through demonstrated rigor.
I have seen the reviews. They read like a critical but fair Reviewer 2, the kind of reviewer you respect even when they make you revise. They check the math. They flag assumptions. They note limitations. And they are applied to every single study, at scale, automatically. No evidence reaches a clinician without having been AI reviewed.
Layer 4: Human Oversight
Automated review is necessary but not sufficient. There must always be a path to human judgment.
Two mechanisms exist for this. First, a percentage of the entire evidence library is continuously undergoing third-party human review. This is not a token gesture. It is a systematic quality audit, conducted by independent reviewers, that tests the AI review system against human judgment on an ongoing basis.
Second, and perhaps more importantly, any user who receives a generated study can request an expert clinician review with a single click. A human clinician, a real doctor, will review the study, assess its accuracy and relevance, and provide a written evaluation. This is available for any answer, at any time, at the user’s discretion.
The principle is simple: you should always have transparency, all the way down to how the evidence was generated. And if you want human oversight, you should always have it. These are not competing values. They are complementary layers of the same trust architecture.
The Stack in Practice
Let me put this all together for our PAH patient. Her pulmonologist receives the generated study on Sotatercept safety for patients with thrombotic histories. At the top of the report is a real world fitness score, high, because the underlying dataset contained a substantial population of PAH patients with relevant comorbidity profiles including thrombotic events. Also included is the AI review results: Pass with Notes, with a notation that follow-up duration is shorter than ideal for a progressive disease and sample sizes for the most complex subgroups are modest. The pulmonologist reads the review, understands the limitations, and sees that the directional finding, benefit from Sotatercept in patients with thrombotic history, is consistent with published real-world evidence and biologically plausible given the mechanism of action. If the doctor wants additional assurance, they click a button and a human specialist reviews the study within hours.
Every layer is visible. Every layer is accessible. And the doctor makes the treatment decision, not the AI, not the algorithm, not the system. The doctor. Armed with evidence that did not exist yesterday, reviewed through a process that is more rigorous than what most published studies receive, and supported by human oversight that is available on demand.
This is what I mean when I say the eval is the product. The generation of evidence is the engine. The trust architecture is what makes it usable. And the combination of the two, evidence on demand, trusted by default, is what I believe will define the next era of medicine.
Part III will show how that evidence, generated, trusted, and ready, reaches the people who need it: clinicians at the point of care, payers making coverage decisions, pharmaceutical companies developing therapies, and the AI systems that are increasingly mediating all of it.
Part III: Where Evidence Meets Action
Parts I and II described a problem and a paradigm.
The problem: an evidence system that fails the majority of clinical decisions, excludes the majority of patients, and takes years to deliver what it does produce.
The paradigm: the ability to generate new evidence on demand, from real patient data, at publication-grade rigor, in seconds, with a trust architecture that is more transparent than most of what the traditional system produces.
But a paradigm that exists only in the abstract is worth nothing. Evidence that is generated but never reaches a doctor’s hands at the moment of decision is evidence that might as well not exist. The infrastructure I described in Part II matters only to the extent that it changes what happens in the real world, in exam rooms, in coverage decisions, in drug development pipelines, and in the AI systems that are increasingly mediating healthcare for patients and clinicians alike.
Part III is about that connection. It asks, for each of the major actors in the healthcare system: what changes when evidence is no longer scarce?
Section 7: For Clinicians. Evidence at the Point of Care
Our pulmonary arterial hypertension (PAH) patient has a pulmonologist appointment tomorrow morning. Her pulmonologist, the one who searched the literature in Section 1 and found silence, is about to have a very different experience.
Before the visit, the pulmonologist opens the electronic health record. Next to the patient’s name, there is something new: evidence, pre-populated into the clinical note, specific to this patient’s conditions. The Sotatercept safety study for PAH patients with thrombotic histories, the study that did not exist twenty-four hours ago, is already there. Not as a link to search. Not as a suggestion to investigate further. As evidence, with matched cohorts, statistical results, and an “Answered with Evidence” indicator confirming that the finding is drawn from evidence generated from real world data.
The doctor reviews it during preparation. She walks into the exam room informed. She discusses the options with her patient, explains the evidence, and together they make a treatment decision grounded in data specific to patients like her. No guessing. No extrapolation from a trial that excluded patients like her. Evidence.
This is what I have been building toward. Not a better search engine. Not a smarter chatbot. Not a tool that makes the doctor’s job easier at the margins. A fundamental change in what the doctor knows when they walk into the room.
Three Touchpoints Across the Patient Journey
Evidence delivery is not a single interface. It meets clinicians at three distinct moments in the patient journey, each serving a different clinical need.
Before the visit: proactive evidence in the EHR
Evidence is pre-populated into clinical notes before the encounter. The doctor opens their schedule, and the relevant evidence for each patient’s conditions is already there: synthesized from both real world data library and published literature. This reduces preparation time and ensures that no patient walks into the room without their doctor having access to the best available evidence for their specific profile.
During and after the visit: personalized evidence through ambient integration.25
As the clinical encounter is documented, increasingly through ambient technology that captures the conversation and generates the note automatically, the evidence layer activates again. It identifies the clinical questions discussed during the visit and surfaces matched evidence directly into the assessment and plan. The doctor does not have to pause, search, or switch systems. The evidence arrives as part of the documentation workflow itself, complete with statistical detail and source attribution.
In care team discussions: on-demand evidence for shared decision-making
The most complex clinical decisions are not made by a single doctor in an exam room. They are made by care teams, in tumor boards, in the collaborative discussions where specialists pool their expertise around a complex patient. Evidence delivery extends into these settings, surfacing relevant studies in real time during the conversation. A clinician discussing a bladder cancer case can query the evidence agent within the care team discussion and receive matched studies without leaving the conversation.
Together, these three touchpoints, preparation, encounter, and collaboration, mean that evidence is not something the doctor goes looking for. It comes to them, wherever they already work, at the moment they need it. The workflow does not change. What changes is what the doctor knows.
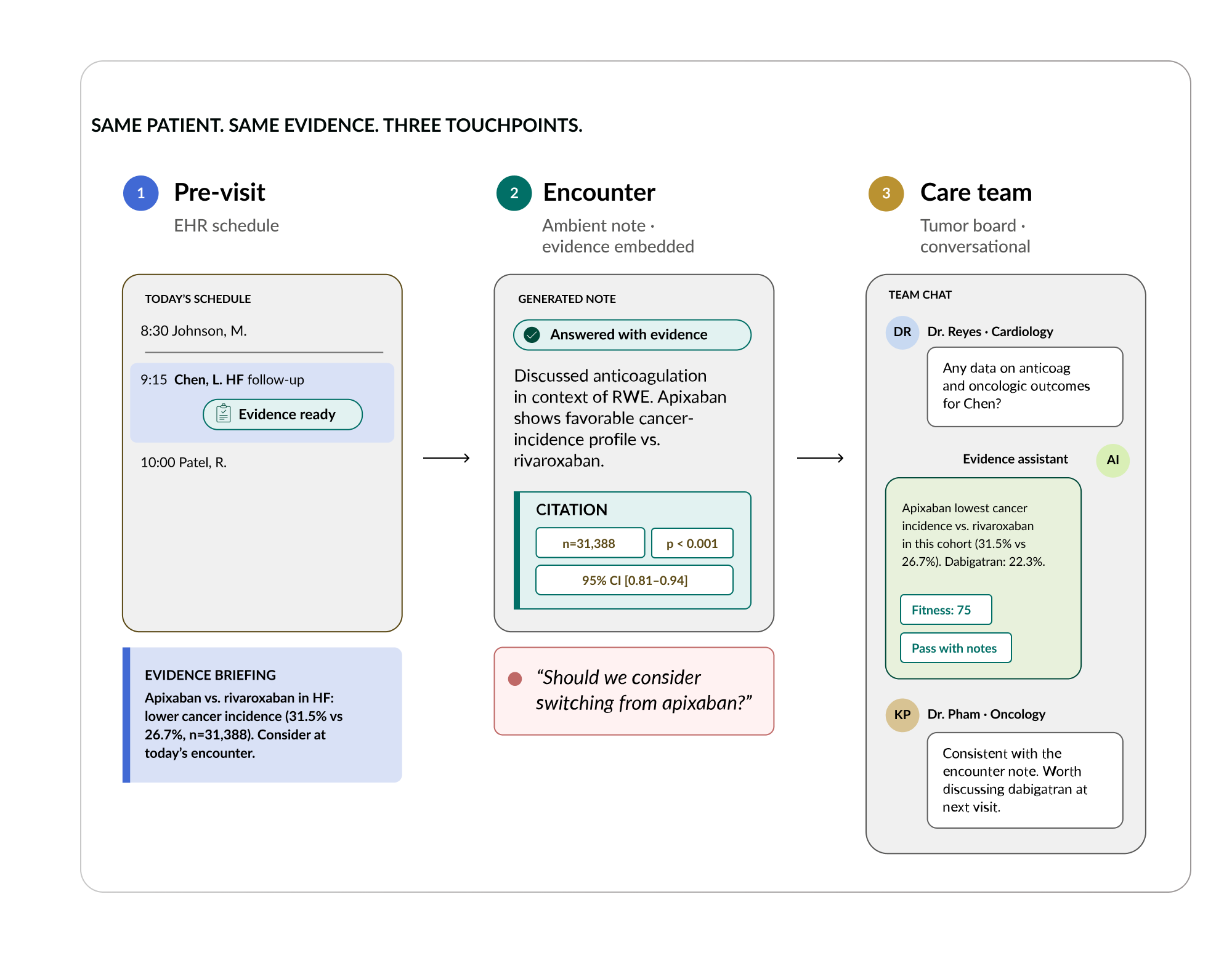
The Doctor Decides
I want to be explicit about something, because I think it matters. In everything I have described, the evidence generation, the trust architecture, the workflow integration, the doctor makes the decision. Not the algorithm. Not the AI. Not the system. The doctor.
The doctor reads the evidence, evaluates it in the context of the patient in front of them, applies their clinical judgment, and decides. The evidence informs. The doctor acts. This is not a semantic distinction. It is a legal reality, the doctor holds the license, carries the liability, and bears the responsibility under tort law for every treatment decision. And it is a moral reality, patients trust their doctor, not a system, to make the right call.
What I am trying to do is ensure that when the doctor makes that call, they are not guessing. They are not extrapolating from a trial that excluded patients like theirs. They have evidence. Specific, rigorous, reviewed evidence for the patient in their care. And with that evidence, they will make great decisions. I believe that completely.
Extending the Physician, Not Replacing Them
There is a narrative in the technology industry that AI will replace doctors. I do not believe this, and the evidence does not support it.26 In radiology, where AI-based image analysis has been deployed for years, the demand for radiologists has actually increased, not decreased. The tools help radiologists process more images, catch more findings, and work more effectively. But every finding still requires a radiologist’s judgment. The same pattern is emerging in dermatology, pathology, and other specialties where AI tools are being adopted: the technology extends what each physician can do, but it does not eliminate the need for the physician.
This matters because we need more physician capacity, not less.27 The United States has been under-training physicians for a decade, and a wave of retirements is approaching that will further strain the system. Evidence at the point of care does not solve the physician shortage directly, but it changes what each physician can accomplish. A doctor equipped with patient-matched evidence for every encounter can make faster, more confident decisions. They spend less time searching and more time treating. And in a system where physician time is the scarcest resource, that extension of capability may be the most practical contribution AI makes to healthcare.
I imagine a future, and I do not think it is far away, in which a physician, equipped with the right evidence and the right tools, can see, decide, and effectively treat ten thousand patients. Not because they are rushing. Not because they are cutting corners. Because the evidence is there for every patient, the workflows deliver it seamlessly, and the doctor’s expertise is applied where it matters most: at the point of judgment. That is not replacement. That is medicine working the way it always should have worked, at a scale that the system desperately needs.
Section 8: For Payers. Evidence-Based Authorization and Coverage
Now imagine the next step in our patient’s journey. Her pulmonologist has reviewed the evidence. They have discussed the options. Together, they have decided to add Sotatercept. The pulmonologist writes the prescription. And then, in the current system, something happens that has nothing to do with clinical judgment and everything to do with administrative machinery: prior authorization is triggered.
The payer requires justification. The pulmonologist must demonstrate that the treatment is medically necessary, that it meets the payer’s coverage criteria, and that it is supported by evidence. But the guidelines, the very guidelines whose limitations we explored in Section 3, do not address Sotatercept for pulmonary arterial hypertension (PAH) patients with thrombotic risk. The evidence the pulmonologist now has, generated in seconds from matched real-world patients, does not exist in the guideline framework the payer uses to evaluate the request.
The result, in the current system, is delay. Or denial. Or hours of the doctor’s time spent on phone calls, fax machines, and appeals: arguing for a treatment that the evidence clearly supports, to a system that cannot recognize evidence it was not designed to accept.
Prior authorization is one of the most universally despised processes in healthcare.28 Physicians report spending an average of nearly two business days per week on prior auth activities. Patients experience delays in care that can range from days to weeks. The administrative cost to the system runs into the tens of billions annually.29 And every participant, the doctor, the patient, the payer, loses.
I want to be clear about something: I am not here to attack payers. Prior authorization exists because payers face real cost-control pressures and must make decisions about what to cover with limited information. When evidence is incomplete, and we have established that it is incomplete 86% of the time, bureaucratic gatekeeping becomes the default mechanism for managing uncertainty. It is blunt, it is adversarial, and it is slow. But from the payer’s perspective, it is rational. They are trying to ensure that treatments are appropriate, with insufficient evidence to make that determination efficiently.
The prior authorization problem is not, at its root, an operational problem. It is an evidence problem.
The Payer Has Already Moved
Here is what makes this particularly urgent: payers already recognize real-world evidence as their most valuable evidence type. As we saw in Section 3, RWE accounts for 39% of citations in 2024–2025 coverage policies from major U.S. insurers: more than systematic reviews, more than RCTs.30 The payer system has already shifted toward the evidence type that best reflects real-world clinical reality. What has not shifted is the infrastructure connecting that evidence to the authorization process.
The clinician, meanwhile, is caught between two evidence standards. They follow guidelines where RWE accounts for just 12% of citations.31 When they submit a prior authorization request, they are often citing guideline-based evidence that the payer’s own policies have already moved beyond. The doctor is speaking one evidentiary language. The payer is listening in another. And the patient waits while the two systems fail to communicate.
What Evidence-Based Authorization Looks Like
Now imagine a different system. Our pulmonologist prescribes Sotatercept for the PAH patient with thrombotic history. The prior authorization process is triggered, but instead of a manual justification, the generated evidence travels with the request. The study showing outcomes for PAH patients with thrombotic histories on Sotatercept, complete with matched cohorts, statistical results, a data fitness score, and an AI review verdict, is submitted as part of the authorization. The payer, who already relies on RWE for 39% of their coverage decisions, receives evidence in the format they already trust.
The authorization is not automatic. The payer still evaluates the evidence against their coverage criteria. But instead of an adversarial, paper-based process that takes days or weeks, it is an evidence-based review that can happen in hours or minutes. The doctor does not spend two days a week on phone calls. The patient does not wait weeks for a treatment their doctor has already determined is appropriate. And the payer gets what they actually need: evidence that the treatment is effective for this specific patient population, presented in a format that supports efficient decision-making.
But faster authorization is only part of what changes. Consider what happens today when a prior authorization is denied. The physician appeals. The appeal is built on the same incomplete evidence that failed the first time, because no better evidence exists. The denial stands. The patient either goes without the treatment or endures weeks of administrative back-and-forth while their condition progresses. In PAH, where the disease is remodeling pulmonary vasculature in real time, every week of delay has clinical consequences.
With generated evidence, the appeal is built on something the old system never had: patient-matched data showing outcomes for the specific population in question. The physician is no longer arguing from analogy or extrapolation. They are presenting a study. The payer is no longer evaluating a justification. They are evaluating evidence. The win rate on appeals changes, because the quality of what is being appealed changes. And each successful appeal, grounded in rigorous evidence, builds a precedent that strengthens future authorizations for similar patients.
Now take this one step further. If the evidence for a specific treatment in a specific patient population is strong enough, consistent enough, and trusted enough, the prior authorization requirement itself becomes unnecessary. The payer already has the evidence in the system. The treatment has already been validated for this population through generated studies that meet the payer’s own evidentiary standards. The authorization is pre-approved, not because the system is cutting corners, but because the information the authorization process was designed to produce already exists. The bureaucratic step that consumed two days of a physician’s week, delayed patient care, and cost the system tens of billions of dollars annually becomes redundant, not by removing the safeguard, but by satisfying it in advance.
This is the full arc of what evidence-based authorization makes possible. It speeds up the process that exists today. It strengthens appeals with real evidence when denials occur. And ultimately, for well-evidenced treatments in well-studied populations, it eliminates the need for the process altogether. Every component of this workflow exists today. The evidence can be generated. The trust architecture provides the quality signals payers need. The delivery infrastructure can attach evidence to authorization requests. What is missing is the connection, the infrastructure that links evidence generation to the authorization process. And I believe that connection is coming, because the incentives align for every participant in the system.
The Value-Based Care Connection
There is a broader dimension to this that extends beyond prior authorization. As the healthcare system moves toward value-based care, contracts that tie reimbursement to outcomes rather than volume, the demand for evidence-based coverage decisions intensifies. Value-based contracts require knowing what works for specific patient populations, which treatments produce the best outcomes at the lowest cost, and how to allocate resources effectively across a diverse patient population.
This is exactly what evidence generation produces at scale: patient-matched evidence of treatment effectiveness, generated across every subgroup, with the rigor and transparency that value-based contracts demand. The payer who can make evidence-based coverage decisions, rather than relying on guidelines that are four to six years old and were built primarily on systematic reviews and RCTs, has a structural advantage in a value-based system.
The shift I am describing is not about making prior auth faster. It is about making the entire relationship between evidence and coverage decisions more rational, more efficient, and ultimately better for patients. When evidence is abundant, specific, and trusted, the need for adversarial gatekeeping diminishes. Not because cost control is no longer necessary, but because the information needed to make good decisions is finally available.
Section 9: For Life Sciences. Reshaping Drug Development
There is another actor who has been watching our patient’s story unfold, though she does not know it. Somewhere, a pharmaceutical company developed Sotatercept. It was approved for pulmonary arterial hypertension (PAH) based on clinical trials that excluded patients with thrombotic risk, abnormal hematological profiles, and bleeding risk. The company knows it works for the approved population. What they did not know, until now, is how it performs in the complex, comorbid patients who were screened out of the pivotal trials. They did not know because the evidence did not exist.
Now it does. And it did not come from a seven-year clinical trial. It came from the evidence library: generated across hundreds of thousands of matched patients, reviewed by the trust architecture I described in Section 6, and available today. What the company is looking at is a label expansion opportunity: a new indication for an existing drug, supported by real-world evidence, achievable in a fraction of the time and cost of a traditional trial.
This is where evidence generation intersects with the economics of drug development, and it is an area I have been cautious about discussing publicly because the implications are so large that they can sound like hyperbole. They are not. Let me explain why I think this may be the most underestimated dimension of what evidence on demand makes possible.
The Current Economics
Drug development, classically, takes eight to twelve years from initial concept to market approval.32 Current estimates place the average at seven to nine years, reflecting some recent efficiency gains. The cost is measured in billions. A single drug, from discovery through Phase III trials and regulatory approval, can consume north of a billion dollars in capital before a single patient benefits from it.
The traditional pathway for expanding a drug’s label, getting approval for a new indication, a new patient population, a new use, typically mirrors the original approval process: a new clinical trial, new data, new regulatory submission. For an existing drug with a well-established safety profile, this can mean seven or more additional years to prove what real-world patient data already suggests.
But this is beginning to change. The FDA has signaled increasing openness to real-world evidence as a basis for regulatory decisions.33 And recently, the agency approved a drug for a new indication based entirely on real-world evidence, with no new clinical trial. That decision compressed what would normally have been a seven-year process. It is, I believe, a signal of where the regulatory system is headed.
More Bets, Not Less Capital
When I talk to people about the economics of evidence-based drug development, the first assumption is usually cost savings. If drug development is faster, it must be cheaper, right? That is partly true. But the more important insight is about capital allocation, not capital reduction.
Think about how a pharmaceutical company is structured today. It is, in essence, a very large, very expensive betting machine. It places a small number of enormous bets: each one costing billions of dollars and taking a decade to resolve. Most of those bets fail. The ones that succeed must generate enough revenue to cover all the failures. This is the fundamental economic structure of the industry, and it drives everything from drug pricing to research priorities to which patient populations get studied.
Now imagine a world where evidence generation can tell you, before you spend a billion dollars on a clinical trial, whether a drug is likely to work for a specific population. Where label expansions can be pursued based on real-world evidence in months rather than years. Where the safety profile of an existing drug can be evaluated across patient subgroups that were never included in the original trial.
You are still going to spend ten billion dollars. But you are going to make a lot more bets. And those bets are going to be far more precise, because each one is informed by evidence that already exists. The pharmaceutical company of the future does not spend less. It deploys its capital with more precision, across more opportunities, with a higher probability of success for each one.
I see this playing out already in markets like China, where I am watching thousands of mini biotechs spin up therapies that can be tested and potentially approved in months rather than years. The decentralization of drug development, enabled by evidence generation, is not a distant possibility. It is beginning to happen.
The Opportunities
The implications extend across the life sciences value chain.
Label expansion is the most immediate opportunity. Thousands of existing drugs have well-established safety profiles and could be effective for patient populations that were never included in their original trials. Evidence generation can identify these opportunities and provide the evidentiary basis for regulatory submission.
Drug repositioning, finding entirely new uses for existing drugs, becomes systematically discoverable rather than serendipitous. When you have an evidence library covering billions of patient-drug-outcome combinations, patterns emerge that no individual researcher could have identified.
Rare diseases represent a category where the traditional trial system is structurally incapable of operating. A condition that affects a few thousand patients globally cannot support a traditional RCT, the enrollment is too small, the timelines too long, the economics impossible. But those patients exist in the data. They have been treated, and their outcomes have been recorded. Evidence generation can produce studies for patient populations that the traditional system could never reach.
Post-market surveillance, monitoring the safety and effectiveness of drugs after they reach the market, can shift from slow, passive reporting systems to active, continuous evidence generation across the full patient population.
Each of these opportunities represents not just a scientific advance but an economic restructuring. If evidence generation reduces the time and cost of label expansion, it changes the calculus of which drugs get developed and for whom. If it makes rare disease research feasible, it opens therapeutic areas that were previously uneconomic. If it enables more precise capital allocation, it changes the structure of pharmaceutical companies themselves.
I hold myself back when I talk about this publicly, because the implications are so broad that they risk sounding like a pitch. They are not. They are a description of what the evidence trajectory I described in Part II makes possible when applied to the economics of therapeutic development. And I believe the total impact is still vastly underestimated.
Section 10: For AI Systems. The Missing Evidence Layer
There is one more audience for the evidence I have described, and it is perhaps the one with the most consequential implications for the future of healthcare: the large language models and AI systems that are rapidly entering the clinical space.
Let me return to our patient one final time in this section. Remember, in Section 1, her pulmonologist asked an AI tool about Sotatercept for a pulmonary arterial hypertension (PAH) patient with thrombotic risk. The AI cited the HYPERION and STELLAR trial data and noted, accurately, that patients with thrombotic histories were excluded. The best AI tools do this well, they accurately report the state of the published evidence and flag when the evidence is insufficient. The worst ones give a confident answer anyway, based on extrapolation that they present as fact. In healthcare, that extrapolation has a name: hallucination. And in healthcare, hallucination can be lethal.
But here is the thing I want people in the AI industry to understand: the problem is not the AI. The problem is the evidence base the AI is drawing from. A large language model can only retrieve and synthesize what has been published. It cannot generate knowledge that does not exist. When the evidence does not exist, which is 86% of the time for clinical decisions, even the best AI system hits a structural ceiling. No amount of compute, no improvement in architecture, no refinement of prompting strategy can overcome this. You cannot summarize your way to an answer that has never been produced.
The Evidence Layer AI Needs
The implication is straightforward: if AI systems are going to be trustworthy in healthcare, they need access to an evidence base that is far larger, far more specific, and far more current than what the published literature provides. They need an evidence generation layer.
This is not a competitive claim. I am not arguing that AI tools should be replaced by evidence generation tools. I am arguing that they are complementary, that the LLM is the interface, and the evidence engine is the knowledge source. The AI becomes the way patients and clinicians interact with the system. The generated evidence becomes what the system actually knows.
The data supports this. When we evaluated how well different systems answer physician questions with evidence, across 5,000 clinical questions, the results were telling.34 The leading general-purpose LLMs top out at roughly 50% of questions answered with relevant, evidence-based responses. Traditional clinical reference tools perform in a similar range. Evidence generation systems reach approximately 75% or higher on the same metric.
The structural reason for this gap is exactly what I have been describing throughout this manifesto: LLMs can only summarize what is published. Evidence generation creates what is missing. The 25-percentage-point gap between 50% and 75% is not a quality gap, it is an existence gap. The evidence literally does not exist for the LLMs to find. You cannot close this gap with better prompting, larger models, or more compute. You can only close it with more evidence.

The Training Proof
There is a second dimension to this relationship that I think is equally important. It is not just that AI systems need generated evidence at inference time, when they are answering a specific question. They also need it at training time, when they are building their foundational understanding of healthcare.
We have seen this demonstrated directly. When a leading open-source large language model was tuned with generated evidence content and evidence-based training data, its healthcare performance improved measurably across nearly every dimension of a standard healthcare benchmark: communication quality, accuracy, complex response handling, context awareness, emergency referrals. The tuned model exceeded the overall benchmark performance of a major commercial LLM. This is not theoretical. It is measured, on a recognized evaluation framework, with reproducible results.
The message is simple: evidence generation does not just answer questions. It makes entire AI systems better at healthcare. And major AI companies are beginning to recognize this. The relationship between evidence generation platforms and AI companies is evolving from one of parallel development to one of infrastructure dependence. The AI systems need the evidence library to improve. And the evidence library grows more valuable as more AI systems draw from it.
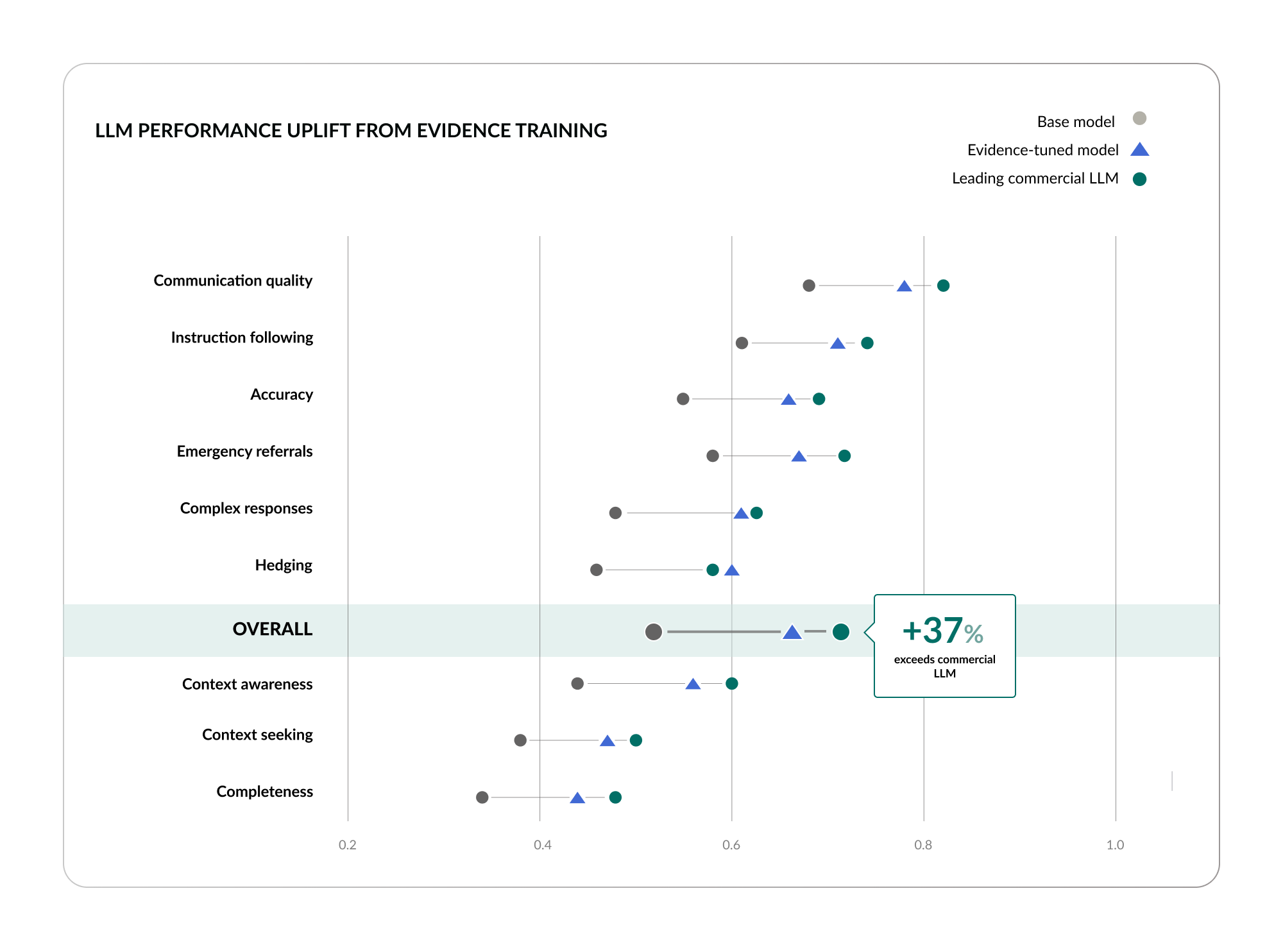
The Hallucination Problem, Reframed
There has been enormous attention in the last two years to the problem of AI hallucination in healthcare. Much of that attention has focused on guardrails: ways to prevent AI systems from generating false or misleading clinical information. Guardrails are important. But they are, ultimately, a defensive strategy. They address the symptom without addressing the cause.
The cause is the evidence gap. AI systems hallucinate in healthcare because there are vast regions of clinical space where no evidence exists to anchor their responses. In those regions, the model must choose between admitting uncertainty and generating a plausible-sounding answer. The former is honest. The latter is dangerous. And no guardrail can eliminate the temptation to fill silence with noise.
The real solution is not better guardrails. It is more evidence. Fill the evidence gap, and you fill the space where hallucination lives. Give the AI system access to generated evidence for every patient subgroup, every drug comparison, every clinical scenario, and the model no longer needs to extrapolate. It can cite. It can reference. It can ground its answers in evidence that actually exists.
This is the future I am building toward: not a world where AI competes with evidence, but a world where AI is built on top of it. The AI is the interface. The evidence is the foundation. And the patient, our patient, the one with PAH and a thrombotic history, gets an answer that is not a guess, not a hallucination, not a summary of a trial that excluded her. She gets an evidence-based answer, generated from patients like her, reviewed for rigor, and delivered through whatever interface she or her pulmonologist prefers.
The Picture, Assembled
Step back for a moment and consider what Part III has described in total.
A clinician opens her schedule tomorrow morning and finds evidence waiting for every patient, not generic literature summaries, but studies matched to each patient’s specific profile, generated from real-world data, reviewed for rigor, and embedded in the workflow she already uses. She walks into the exam room informed. She walks out having made a decision grounded in evidence that did not exist a day earlier.
A payer receives an authorization request for that same patient, and instead of an adversarial exchange built on incomplete guideline citations, they receive the evidence itself: transparent, reviewed, specific to the patient population in question. The authorization takes minutes instead of weeks. The patient gets the treatment their doctor prescribed without delay.
A pharmaceutical company sees patterns across hundreds of thousands of patients in the evidence library and identifies a label expansion opportunity for an existing drug: achievable in months rather than the seven years the traditional pathway would require. Capital flows not into a few massive, uncertain bets, but into dozens of precise ones, each backed by evidence that already exists.
And an AI system, trained not just on the published literature but on a generated evidence library orders of magnitude larger, can answer the clinical questions that every other system hits a wall on. Not by guessing. Not by extrapolating. By citing evidence that was produced for the specific patient, the specific condition, the specific combination of factors that make each clinical question unique.
Each of these changes is significant on its own. Together, they describe a healthcare system that operates on a fundamentally different evidentiary foundation, one in which the currency of value is no longer scarce, no longer outdated, and no longer blind to the patients who need it most. The clinician is informed. The payer is rational. The developer is precise. The AI is grounded. And the patient, every patient, including the ones the old system left behind: has evidence behind the care they receive.
This is not incremental. It is not an optimization of the existing system. It is a shift in the operating logic of healthcare, from a system built on evidence scarcity to one built on evidence abundance. And it raises a question that I have been circling throughout this manifesto, a question that I believe has become urgent enough to deserve its own answer.
If we can generate evidence for every patient, review it with more rigor than most published studies receive, deliver it to every clinician at the moment of decision, and make it available to every AI system and every payer and every researcher who needs it, if all of this is possible, and I have spent the last three parts arguing that it is, then what, exactly, are we waiting for?
Part IV is my answer.
Part IV: The Future We're Building
I ended Part III with a question: if all of this is possible, what are we waiting for?
It is not a rhetorical question. There are real barriers, institutional, regulatory, cultural, and economic, that stand between the future I have described and the healthcare system as it operates today. Part IV confronts those barriers honestly. It also confronts the most persistent anxiety surrounding AI in healthcare: the fear that technology will replace the humans at the center of it. And it closes with the vision that has driven every decision I have made for the last decade, a vision for what medicine looks like when the evidence gap is closed.
Section 11: AI as Extension, Not Replacement
Before I describe the future, I need to address the fear. Because the fear is real, and it is reasonable, and if I do not engage with it directly, everything else I say will be filtered through it.
The fear is this: that AI will replace doctors. That the technologies I have been describing, evidence generation, automated review, workflow integration, AI systems trained on generated evidence, are steps along a path that ends with physicians becoming unnecessary. That the logical endpoint of making evidence abundant and accessible is making the people who interpret it redundant.
I do not believe this. And I want to explain why with something more substantial than reassurance.
What the Evidence Actually Shows
Consider radiology. AI-based image analysis in radiology has been deployed at scale for several years now. The technology is good, in some narrow tasks, it matches or exceeds human performance. If the replacement thesis were correct, we should be seeing a decline in demand for radiologists. We are not.35 Demand for radiologists has actually increased. Why? Because AI tools process more images, flag more findings, and surface more cases that require expert review. The technology does not eliminate the need for human judgment. It generates more work that requires it.
The same pattern is emerging in dermatology, where AI can evaluate skin lesions at scale, but the dermatologist still makes the treatment decision, with their license, their liability, and their relationship with the patient on the line. And in pathology, where AI assists with slide analysis but the pathologist’s interpretation remains definitive.
In every specialty where AI tools have been meaningfully deployed, the pattern is the same: the technology extends the physician’s capability without replacing their role. It allows them to see more, process more, and know more, but the decisions remain theirs. The judgment remains theirs. The accountability remains theirs.
The Distinction That Matters
The distinction is between tasks and judgment. AI is extraordinarily good at automating tasks: transcribing clinical notes, processing images, synthesizing literature, flagging anomalies, generating evidence from data. These are activities that consume enormous amounts of physician time but do not, in themselves, constitute the practice of medicine. They are the infrastructure of practice, not the substance of it.
The substance of medicine is judgment: evaluating evidence in the context of a specific patient, weighing risks and benefits, communicating with the patient, making a shared decision, and taking responsibility for it. This is what physicians are trained for. This is what patients need from them. And this is what no AI system I have seen or built is capable of replacing.
My wife is a physician. I watch her practice. I see the way she synthesizes information that no algorithm captures, the patient’s body language, their unspoken concerns, the context of their life, the nuance of a conversation that reveals more than any medical record could. The idea that an algorithm will replace that is not just wrong. It reflects a fundamental misunderstanding of what medicine is.
What AI can do, what evidence generation specifically can do, is ensure that when my wife makes a clinical judgment, she has the best possible evidence to inform it. That is a different proposition entirely. It is not making the doctor unnecessary. It is making the doctor more effective, more informed, and more confident in the decisions they are already responsible for making.
A Capacity Problem, Not a Replacement Problem
There is a pragmatic dimension to this that I think is often overlooked in the replacement debate. The United States is not facing a surplus of physicians. It is facing a shortage.36 We have been under-training doctors for over a decade, and a wave of retirements, particularly in primary care, is approaching that will further strain a system already stretched thin. The challenge is not too many doctors. It is too few.
In this context, the question is not whether AI will replace physicians. The question is whether AI can help the physicians we have serve more patients, more effectively, without burning out. And here, I think the answer is clearly yes.
A doctor who opens her schedule and finds evidence already waiting for every patient spends less time searching and more time treating. A doctor whose clinical notes are generated automatically and enriched with relevant evidence spends less time on documentation and more time on the patient in front of them. A doctor participating in a tumor board discussion with evidence available in real time makes faster, more confident recommendations.
None of these examples replace the doctor. They free the doctor to do what only a doctor can do. And in a system where physician time is the scarcest and most valuable resource, that extension of capability is not a threat to the profession. It is the profession’s most promising lifeline.
I imagine a future in which a physician, equipped with the right evidence and the right tools, can see and effectively treat ten thousand patients. Not because they are being replaced by a machine. Because they are being extended by one. Because the evidence is there for every patient, the workflows deliver it seamlessly, and the doctor’s judgment is applied where it matters most. That is not the end of medicine. It is medicine finally working the way it was supposed to.
Section 12: The Vision
I started this manifesto with a patient. A woman with pulmonary arterial hypertension, sitting in a doctor’s office after years of being told she had asthma, then COPD, while her actual disease progressed silently. I described her not because she is unusual, but because she is ordinary. She is the norm. She is the 86%.37
I have spent twelve sections tracing the architecture of that silence: why the evidence does not exist, who it fails, how the pipeline bottlenecks, and what it means that the economic and clinical systems of healthcare have diverged in what they recognize as evidence. I have described a paradigm shift from retrieval to generation, a trust architecture that makes generated evidence rigorous and transparent, and the specific ways that evidence on demand changes the operating logic for clinicians, payers, pharmaceutical companies, and AI systems.
Now let me tell you what I see.
The World I Am Building Toward
I see a world in which no doctor faces a patient and finds silence. In which the evidence gap, that 86% of decisions made without evidentiary support, is closed. Not gradually, over decades of incremental progress through the traditional pipeline. But decisively, through the generation of evidence at a scale and speed that matches the pace of clinical need.
The trajectory is already extraordinary. We generated 33 million study equivalents in a single quarter. The current run rate is 930 million. The projection for the end of this year is 2 billion.38 For context, the entire published biomedical literature, everything in PubMed, accumulated over more than a century, contains approximately 37 million studies. We will exceed that by orders of magnitude within the year. And each generated study is not a summary of existing knowledge. It is new knowledge, created from real patient data, for specific patient populations that the traditional system never reached.
I see a world in which the populations left behind by the old evidence system, the elderly, women, children, racial and ethnic minorities, and above all the 70% of patients who are comorbid and were systematically excluded from the trials that govern their care, have evidence. Not because someone finally got around to studying them. Because evidence generation does not depend on someone deciding they are worth studying. It generates evidence for everyone, across every subgroup, as a matter of infrastructure.
I see a world in which the five-year bottleneck from discovery to practice collapses. In which a researcher’s hypothesis can be tested in seconds rather than months. In which evidence flows into guidelines, into coverage policies, and into clinical practice not over years but over weeks. In which the currency of healthcare value, evidence, is no longer scarce, outdated, or blind to the patients who need it most.
I see clinicians who practice medicine the way it was always meant to be practiced: armed with evidence specific to the patient in front of them, delivered seamlessly into their workflow, reviewed for rigor, and available at the moment of decision.
I see payers who make coverage decisions based on real-world evidence for real-world patients, not on guideline citations from 2018.
I see pharmaceutical companies that deploy capital with precision across hundreds of opportunities, each backed by evidence, each resolved in months rather than decades.
I see AI systems that are grounded in generated evidence rather than limited to the published literature: systems that can answer the questions that matter, for the patients that matter, without hallucination.
And I see our patient. The woman with pulmonary arterial hypertension (PAH) and a history of venous thromboembolism. In the version of her story that the old system wrote, she lost nearly two years to misdiagnosis, was treated for conditions she did not have, and by the time anyone got the answer right, her right ventricle was already failing. The most promising therapy available was one that no trial had ever studied in a patient like her. She waited. She deteriorated. She had no evidence and no options.
When the evidence gap is closed, she does not lose those years. The patterns in her data are flagged early. She is referred to a pulmonary hypertension center before her disease has progressed beyond the window for intervention. She is correctly diagnosed. She starts appropriate background therapy. And when her pulmonologist considers adding Sotatercept, the evidence is already there, generated from thousands of patients with her profile, including her thrombotic history, reviewed for rigor, delivered into the clinical note before her appointment.
Her pulmonologist explains the findings. They discuss the risks, the benefits, the caveats the peer review flagged. Together, they decide. The prescription is written. The prior authorization includes the evidence. The payer approves. She starts disease-modifying therapy while her disease is still early enough to modify.
Six months later, her functional status has improved. She walks further. She breathes easier. Her right ventricle is stable. She is not on a transplant list. She is not wondering what went wrong. She is living the life that evidence made possible, because someone built the system to generate it, and someone trusted it enough to act on it.
That is the future I see. Not for one patient. For every patient. For the grandmother on seven medications. For the child whose treatment was extrapolated from an adult trial. For the millions of patients whose clinical reality was too complex for the evidence system that was supposed to serve them. Evidence, at the point of care, for every patient who needs it.
That is not a distant future. The infrastructure exists. The methodology is proven. The scale is already surpassing the entire published evidence base. The trust architecture is operational. The delivery channels are live. Every piece of what I have described in this manifesto is either working today or in advanced stages of deployment.
The Barriers
I would be dishonest if I claimed there are no barriers. There are. And they are worth naming, because naming them is the first step toward removing them.
Regulatory adaptation
The FDA has signaled openness to real-world evidence, and recent regulatory decisions have demonstrated that the agency is willing to act on it. But the regulatory framework is still built primarily around the randomized controlled trial as the gold standard. Expanding the formal role of generated real-world evidence in regulatory decision-making, for label expansions, for post-market surveillance, for safety signal detection, will require continued engagement between evidence generators, regulators, and the clinical community. This is happening, but it is not finished.
Guideline infrastructure
As I documented in Section 3, the guideline system operates on a cycle that lags years behind both the evidence and the economic system. Guideline committees must develop processes for evaluating generated evidence alongside traditional study types. This is a cultural shift as much as a procedural one, and cultural shifts in medicine take time.
Institutional adoption
Health systems are conservative institutions, for good reason. Integrating evidence generation into clinical workflows requires trust, training, and infrastructure investment. The technology must prove itself in each new setting, with each new user population, against each new set of clinical questions. This is the patient work of building something that lasts, brick by brick. It cannot be rushed, and it should not be.
The orthodoxy of scarcity
Perhaps the most subtle barrier is psychological. The healthcare system has operated under evidence scarcity for so long that scarcity has become embedded in its assumptions, its workflows, and its culture. Doctors are trained to work with incomplete information. Payers are structured around managing uncertainty. Guidelines are designed to be conservative because the evidence they draw from is limited. The shift to evidence abundance requires not just new technology but a new mindset, a willingness to believe that the constraints we have always operated under are no longer immovable. This is the hardest barrier to name and the hardest to overcome, precisely because it feels like common sense until the evidence proves otherwise.
The Obligation
I come back, finally, to where I started. I have been carrying this essay for a long time. Not because I enjoy writing long documents. Not because I think manifestos are fashionable. But because I believe something deeply, and I have not yet said it as clearly as I can.
If we have the ability to generate evidence for every patient, including the ones the system has always left behind, and we choose not to, that is not a technology failure. It is a moral one. If a grandmother on seven medications could have evidence-informed care, and we do not provide it because the system was not designed for her, that is a choice. If a child could receive a treatment dosed on evidence generated from pediatric patients rather than extrapolated from adult trials, and we do not generate that evidence because we have always done it the other way, that is a choice. If a patient with a rare disease could have access to studies that the traditional trial system will never run, and we do not run them because we have not yet built the infrastructure to do so at scale: well, that infrastructure now exists.
The evidence gap is not an inevitability. It is an artifact of a system built for a different era. The era has changed. The technology has caught up. The question is whether we will act on what is now possible, or whether we will continue to accept a system that leaves the majority of patients standing outside the cathedral of evidence-based medicine, looking in.
I know my answer. I have known it since 2016, when I sat in front of a microphone and described a future in which a clinician could ask any clinical question, no matter how specific, no matter how complex, and receive rigorous, patient-matched evidence in real time, generated on demand from real-world data. I have known it through every year of building, every brick laid carefully because this matters too much to get wrong. I have known it through every patient whose story I have heard, the grandmother on seven medications, the woman with PAH whose diagnosis took two years, the child whose treatment was extrapolated from an adult trial.
That future is here now. The evidence is flowing. The trust architecture is in place. The delivery channels are live. What I described in 2016 as a vision, evidence on demand, for any question, for any patient, is no longer a vision. It is the present, accelerating.
The only question left is: what are we waiting for?
— Brigham Hyde, PhD
Citations
- Small M, et al. “Diagnostic delay and misdiagnosis in pulmonary arterial hypertension: A multinational real-world survey.” Therapeutic Advances in Respiratory Disease. 2024;18. https://journals.sagepub.com/doi/full/10.1177/17534666231218886
- The term “evidence-based medicine” was popularized by Gordon Guyatt and colleagues at McMaster University in 1992. See: Guyatt GH, et al. “Evidence-based medicine: A new approach to teaching the practice of medicine.” JAMA. 1992;268(17):2420-2425.
- Multiple analyses have documented the systematic exclusion of elderly patients from clinical trials. See, e.g., Cherubini A, et al. “The persistent exclusion of older patients from ongoing clinical trials regarding heart failure.” Archives of Internal Medicine. 2011;171(6):550-556.
- Source: See, e.g., Liu KA, Mager NAD. “Women’s involvement in clinical trials: historical perspective and future implications.” Pharmacy Practice. 2016;14(1):708.
- Source: Smyth RL, Weindling AM. “Research in children: ethical and scientific aspects.” The Lancet.
- Source: Clark LT, et al. “Increasing Diversity in Clinical Trials: Overcoming Critical Barriers.” Current Problems in Cardiology. 2019;44(5):148-172.
- Source: Atropos Health internal benchmarking of traditional clinical research workflows.
- Source: Atropos Health internal analysis of citations in active 2024-2025 clinical guidelines.
- Source: Atropos Health internal analysis of guideline citation sources, 2024.
- Source: Atropos Health internal analysis of guideline citation sources, 2005-2024.
- Source: Atropos Health internal analysis of citations of medical policies from major U.S. insurers, in 2024-2025.
- Source: Atropos Health internal analysis of payer medical policy citation composition, 2005-2024.
- Source: Atropos Health internal analysis of evidence availability by question complexity.
- Source: Atropos Health internal analysis of study type performance across patient complexity levels.
- Observational research using patient-level data has been a recognized methodology since the 1980s. For a historical overview, see: Sackett DL. “Rules of evidence and clinical recommendations on the use of antithrombotic agents.” Chest. 1989;95(2 Suppl):2S-4S.
- The foundational technology was developed at Stanford University in collaboration with Nigam Shah, Professor of Medicine and Biomedical Data Science.
- Atropos Health internal data, Q4 2025.
- Atropos Health internal data, Q4 2025.
- U.S. National Library of Medicine, National Institutes of Health.
- Atropos Health internal data, March 2026.
- Atropos Health internal data, March 2026.
- “Using Aggregate Patient Data at the Bedside via an On-Demand Consultation Service.” NEJM Catalyst Innovations in Care Delivery. Vol. 2, No. 10, October 2021. DOI: 10.1056/CAT.21.0224.
- “Using AI to Empower Collaborative Team Workflows: Two Implementations for Advance Care Planning and Care Escalation.” NEJM Catalyst Innovations in Care Delivery. Vol. 3, No. 4, April 2022. DOI: 10.1056/CAT.21.0457.
- Sam Page, Michigan Medicine, January 14, 2026. “Researchers uncover hundreds of emojis in patient records.”
- Atropos Health internal data.
- Association of American Medical Colleges (AAMC). “The Complexities of Physician Supply and Demand: Projections From 2021 to 2036.”
- Association of American Medical Colleges (AAMC). “The Complexities of Physician Supply and Demand: Projections From 2019 to 2034.”
- American Medical Association (AMA). “2024 AMA Prior Authorization Physician Survey.”
- CAQH Index. “2022 CAQH Index: A Decade of Progress.”
- Atropos Health analysis of citations in 2024-2025 medical policies from major U.S. insurers. Observational/RWE represents 39% of total citations.
- Atropos Health guideline citation analysis, 2024. Observational/RWE represents 12% of total study citations in active clinical guidelines.
- Atropos Health internal analysis.
- Food and Drug Administration. “Framework for FDA’s Real-World Evidence Program.” December 2018.
- Atropos Health. “Answered with Evidence” evaluation across 5,000 physician questions.
- Elizabeth Y. Rula, PhD. American College of Radiology, Feb. 5, 2026. “The Radiologist Shortage: A Workforce Update from HPI.”
- Association of American Medical Colleges.. “The Complexities of Physician Supply and Demand: Projections From 2021 to 2036.”
- Small M, et al. “Diagnostic delay and misdiagnosis in pulmonary arterial hypertension: A multinational real-world survey.” Therapeutic Advances in Respiratory Disease. 2024;18.
- Atropos Health internal data, March 2026.